일반적으로 파드 내부에서 실행되는 컨테이너가 기본 호스트 노드의 파일 시스템에 있는 파일에 액세스할 수 없습니다. 파드는 호스트 시스템에서 격리되고 클러스터의 여러 노드 간에 이식 가능하도록 설계되었기 때문입니다.
호스트의 파일 시스템에 대한 액세스를 제한함으로써 쿠버네티스는 컨테이너화된 애플리케이션과 기본 시스템 간의 보안 경계를 적용합니다. 이러한 격리는 잠재적인 보안 위험을 방지하고 파드에서 실행되는 애플리케이션이 실수로 또는 악의적으로 호스트의 중요한 파일에 액세스하거나 수정할 수 없도록 합니다.
그러나 경우에 따라 호스트 파일 시스템의 특정 파일 또는 디렉터리에 대한 파드 액세스 권한을 부여해야 할 수도 있습니다. 예를 들어 호스트와 컨테이너 간에 구성 파일 또는 데이터 디렉터리를 공유해야 할 수 있습니다.
이러한 경우 'HostPath' 유형의 볼륨을 사용하여 호스트에서 Pod로 필요한 파일 또는 디렉터리를 마운트할 수 있습니다. 'HostPath' 볼륨을 사용하면 호스트 시스템이 잠재적인 보안 위험에 노출되고 다른 노드에서 파드의 이식성이 제한될 수 있으므로 주의해서 사용해야 합니다.
hostPath 볼륨
hostPath 볼륨은 노드 파일시스템의 특정 파일이나 디렉터리를 가리킵니다. 동일 노드에 실행 중인 파드가 hostPath 볼륨의 동일 경로를 사용 중이면 동일한 파일이 표시됩니다.
hostPath 볼륨은 퍼시스턴트 스토리지의 한 유형으로 gitRepo나 emptyDir 볼륨의 콘텐츠는 파드가 종료되면 삭제되는 반면, hostPath 볼륨의 콘텐츠는 삭제되지 않습니다. 파드가 삭제되면 다음 파드가 호스트의 동일 경로를 가리키는 hostPath 볼륨을 사용하고, 이전 파드와 동일한 노드에 스케줄링된다는 조건에서 새로운 파드는 이 전 파드가 남긴 모든 항목을 볼 수 있습니다.
hostPath 볼륨을 데이터베이스의 데이터 디렉터리를 저장할 위치로 사용할 생각이라면 다시 고려해볼 필요가 있습니다. 볼륨의 콘텐츠는 특정 노드의 파일시스템에 저장되므로 데 이터베이스 파드가 다른 노드로 다시 스케줄링되면 더 이상 이전 데이터를 볼 수가 없습니다. hostPath 볼륨은 파드가 어떤 노드에 스케줄링되느냐에 따라 민감하기 때문에 일반적인 파드에 사용하는 것은 좋은 생각이 아닙니다.
hostPath 볼륨을 사용하는 시스템 파드 검사
hostPath를 적절하게 사용하는 방법을 살펴보겠습니다. 새로운 파드를 생성하는 대신 이미 이 볼륨 유형을 사용하는 시스템 전역 파드가 있는지 확인해봅시다. 여러 개의 시스템 파드들이 kube-system 네임스페이스에서 실행 중입니다. 다음과 명령어로 조회가 가능합니다.
$ kubectl get pods --namespace kube-system READY STATUS
조회된 파드가 어떤 종류의 볼륨을 사용하는지 살펴보기 위해 다음 명령어를 사용할 수 있습니다. 다음 예시의 파드 이름은 사용 환경 마다 조금씩 다르니 해당 내용을 바로 입력하는 것이 아닌 위 방법으로 확인 후에 입력하는 것이 맞습니다.
$ kubectl describe po fluentd-kubia-4ebc2f1e-9a3e --namespace kube-system
파드가 노드의 /var/log/var/lib/docker/containers 디렉터리에 접근하기 위해 hostPath 두 개를 사용합니다. 다른 파드들도 살펴 보면 대부분이 노드의 로그파일이나 kubeconfig(쿠버네티스 구성 파일), CA 인증서를 접근 하기 위해 이 유형의 볼륨을 사용한다는 것을 볼 수 있습니다.
다른 파드를 검사해보면 그중 어느 것도 hostPath 볼륨을 자체 데이터를 저장하기 위 한 목적으로 사용하지 않는다는 것을 볼 수 있습니다. hostPath는 단순하게 노드 데이터에 접근하기 위해 사용 합니다. 그러나 Minikube로 생성된 것과 같은 단일 노드 클러스터에서 hostPath 볼륨을 퍼시스턴트 스토리지를 테스트하는 데 종종 사용하기도 합니다. 다중 노드 클러스 터에서 퍼시스턴트 데이터를 적절히 저장하는 데 사용하는 다른 유형의 볼륨을 살펴볼 필요가 있습니다.
노드의 시스템 파일에 읽기/쓰기를 하는 경우에만 hostPath 볼륨을 사용한다는 것을 기억해야합니다. 여러 파드에 걸쳐 데이터를 유지하기 위해서는 절대 사용하지 않는 것은 권해드립니다.
다음 내용들도 같이 다루려 했으나 그러면 앞도적인 스크롤의 압박으로 독자분들께서 보는게 쉽지 않을 것 같아 다음 포스팅으로 빼게 되었습니다.
가장 간단한 볼륨 유형은 emptyDir 볼륨으로 어떻게 파드에 볼륨을 정의하는지 살펴봅시다. 이름에서 알 수 있듯이 볼륨이 빈 디렉터리로 시작됩니다. 파드에 실행 중인 애플리케이션은 어떤 파일이든 볼륨에 쓸 수 있습니다. 볼륨의 라이프사이클이 파드에 묶여 있으므로 파드가 삭제되면 볼륨의 콘텐츠는 사라집니다.
emptyDir 볼륨은 동일 파드에서 실행 중인 컨테이너 간 파일을 공유할 때 유용합니다. 그러나 단일 컨테이너에서도 가용한 메모리에 넣기에 큰 데이터 세트의 정렬 작업을 수행하는 것과 같이 임시 데이터를 디스크에 쓰는 목적인 경우 사용할 수 있습니다. 데이터는 컨테이너 자체 파일 시스템에도 쓸 수 있지만 이 두가지 옵션에는 미묘한 차이가 있습니다. 컨테이너의 파일 시스템은 쓰기가 불가할 수도 있고 마운트된 볼륨에 쓰는 것이 유일한 옵션일 수 있습니다.
파드 생성
파드를 실행하기 위한 두 개의 이미지를 사용합니다. 하나는 이미 빌드되어 있는 luksa/fortune과 alpine 리눅스의 nginx입니다. 이제 파드 매니페스트를 생성해봅시다. 다음 예제의 내용을 포함한 YAML 파일을 생성합니다.
apiVersion: v1 kind: Pod metadata: name: fortune spec: containers: - image: luksa/fortune > 첫 번째 컨테이너는 html-generator라고 이름 짓고luksa/fortune 이미지를 실행 name: html-generator volumeMounts: > html이란 이름의 볼륨을 컨테이너의/var/htdocs에 마운트 - name: html mountPath: /var/htdocs - image: nginx:alpine > 두 번째 컨테이너는 web-server라고 이름 짓고 nginx:alpine 이미지를 실행 name: web-server volumeMounts: > 위와 동일한 볼륨을 /usr/share/nginx/html에 읽기 전용으로 마운트 - name: html mountPath: /usr/share/nginx/html readOnly: true ports: - containerPort: 80 protocol: TCP volumes: > html이란 단일 emptyDir 볼륨을 위의 컨테이너 두 개에 마운트 - name: html emptyDir: {}
파드는 컨테이너 두 개와 각 컨테이너에 각기 다른 경로로 마운트된 단일 볼륨을 갖습니다. html-generator 컨테이너가 시작하면 매 10초마다 fortune 명령의 결과를 /var/ htdocs/index.html에 쓰기 시작합니다. 볼륨이 /var/htdocs에 마운트됐으므로 index.html 파일은 컨테이너의 최상단 레이어가 아닌 볼륨에 쓰여집니다.
web-server 컨테이너가 시작 하자마자 컨테이너는 /usr/share/nginx/html 디렉터리(Nginx 서버가 서비스하는 기본 디렉터 리)의 HTML 파일을 서비스하기 시작합니다. 볼륨이 정확한 경로에 마운트됐으므로, Nginx 는 fortune 루프를 실행하는 컨테이너가 작성한 index.html 파일을 서비스합니다. 결과적으로 클라이언트가 파드의 포트 80으로 보낸 HTTP 요청은 fortune 메시지를 응답으로 받습니다.
실행 중인 파드 보기
Fortune 메시지를 보려면 파드의 접근을 활성화해야 합니다. 이 작업은 로컬 머신의 포트를 파드로 포워딩하면 됩니다.
명령어 kubectl port-forward fortune 8080:80
출력 Forwarding from 127.0.0.1:8080>80 Forwarding from [::1]:8080 -> 80
이제 로컬 머신의 포트 8080으로 Nginx 서버에 접근할 수 있습니다. 서버에 접근할 때는 curl 명령어를 사용합니다.
curl http://localhost:8080
몇 분을 기다린 뒤 다시 요청을 보내면 다른 메시지를 받을 것입니다. 이번 포스팅에서 여기까지의 과정은 컨테이너 두 개를 합쳐 어떻게 볼륨이 컨테이너 두 개를 결합시키고 각 컨테이너의 기능을 향상시키는지를 살펴보기 위해 간단한 애플리케이션을 생성한 것입니다.
emptyDir을 사용을 위한 매체 지정
볼륨으로 사용한 emptyDir은 파드를 호스팅하는 워커 노드의 실제 디스크에 생성되므로 노드 디스크가 어떤 유형인지에 따라 성능이 결정됐습니다. 반면 쿠버네티스에 emptyDir을 디스크가 아닌 메모리를 사용하는 tmpfs 파일시스템으로 생성하도록 요청할 수 있습니다. 이 작업을 위해 다음과 같이 emptyDir의 medium을 Memory로 지정합니다.
volumes: - name: html emptyDir: medium: Memory > 이 emptyDir의 파일들은 메모리에 저장
emptyDir 볼륨은 가장 단순한 볼륨의 유형이지만 다른 유형들도 이 볼륨을 기반으로 합니다. 빈 디렉터리가 생성된 후 데이터로 채워집니다. 그런 볼륨 유형 중 하나가 gitRepo 볼륨 유형입니다.
gitRepo
gitRepo 볼륨의 특징은 생성된 후에는 참조하는 리포지터리와 동기화되지 않는다는 것입니다. 깃 리포지터리에 추가 커밋을 푸시해도 볼륨에 있는 파일은 변경되지 않습니다. 그러나 레플리케이션컨트롤러가 파드를 관리하는 경우 파드를 삭제하면 새 파드가 생성되는데 이 때 파드의 볼륨에는 최신 커밋을 포함하게 됩니다.
예를 들어 깃 리포지터리에 웹사이트의 정적 HTML 파일을 저장하고 gitRepo 볼륨과 웹 서버 컨테이너를 가진 파드를 생성할 수 있습니다. 매번 파드가 생성될 때 웹사이트의 최신 버전을 가져와 서비스할 것입니다. 단점은 gitRepo에 변경을 푸시할 때마다 웹사이트의 새 버전을 서비스하기 위해 파드를 삭제해줘야 한다는 점입니다.
gitRepo에 파일 복제 및 서비스 실행
파드를 생성하기 전에 HTML 파일이 있는 실제 깃 리포지터리가 필요합니다. 제가 공부하는 책의 저자는 예제를 위해 https://github.com/luksa/kubia-website-example.git에 깃허브 GitHub 리포지터리를 생성해 주었습니다. 나중에 변경 사항을 푸시하기 위해서 리포지터리를 포크해야 합니다. 깃허브에 리포지터리 복사본을 만드는 것도 방법입니다.
포크를 생성했으면 이제 파드를 생성할 차례입니다. 이번에는 파드에 Nginx 컨테이너 하 나와 gitRepo 볼륨 하나만 있으면 됩니다. gitRepo 볼륨이 예제 리포지터리를 포크한 여러분의 리포지터리를 가리키는지 확인을 한번 더 하면 좋습니다. 아무래도 주소를 직접 타이핑하게 되면 휴먼 리스크(오타)가 발생하기 때문이죠.
파드를 생성하면 볼륨은 먼저 빈 디렉터리를 초기화한 다음 특정 깃 리포지터리를 복제 합니다. directory . (점)으로 지정하지 않으면 의도치 않게 리포지터리가 kubia-website- example 하위 디렉터리로 복제됐을 것입니다. 예제에서 리포지터리는 볼륨의 루트 디렉터리에 복제 돼야 하기 때문에 리포지터리를 지정함과 동시에 볼륨이 생성되는 시점에 쿠버네티스에게 master 브랜치가 가리키는 버전을 체크아웃하도록 지정했습니다.
파드가 실행되면 포트 포워딩, 서비스 또는 파드 내부(혹은 클러스터 내부의 또 다른 파드) 에서 curl 명령을 실행해 호출할 수 있습니다.
포크(fork)하다? "리포지토리를 포크한다"는 것은 Git 및 GitHub, GitLab 및 Bitbucket과 같은 플랫폼에서 버전 제어 시스템의 맥락에서 사용됩니다. 리포지토리를 포크한다는 것은 자신의 계정 또는 네임스페이스에서 기존 리포지토리의 복사본을 만드는 것을 의미합니다. 이를 통해 원래 리포지토리에 영향을 주지 않고 코드베이스를 독립적으로 변경할 수 있습니다.
리포지토리를 포크하는 주된 이유는 오픈 소스 프로젝트에 기여하거나 기존 프로젝트를 작업의 시작점으로 사용하기 위해서입니다. 리포지토리를 포크하면 수정하거나 새로운 기능을 실험하거나 코드베이스의 버그를 수정할 수 있습니다. 포크된 리포지토리를 변경한 후에는 원본 리포지토리에 pull 요청(또는 merge 요청)을 제출하여 변경 사항을 기본 코드베이스에 병합할 것을 제안할 수 있습니다. 프로젝트 관리자는 변경 사항을 검토하고 피드백을 제공하며 기여를 수락할지 거부할지 결정할 수 있습니다.
깃 리포지터리와 파일 동기화 여부 확인
깃허브 리포지터리의 index.html 파일을 변경할 수 있습니다. 로컬에서 깃을 사용하지 않는 다면 깃허브에서 직접 파일을 수정도 가능합니다. 깃허브 리포지터리에서 파일을 클릭해 열고 연필 모양의 아이콘을 클릭하면 편집을 시작합니다. 텍스트를 변경하고 페이지의 맨 아래에 있는 버튼을 클릭해 변경 사항을 커밋합니다.
이제 깃 리포지터리의 master 브랜치에는 변경된 HTML 파일이 들어있습니다. gitRepo 볼륨은 깃 리포지터리와 동기화하지 않기 때문에 이 변경 사항이 Nginx 웹 서버에서는 보이지는 않습니다. 파드를 다시 호출해 확인해봅니다.
웹사이트의 새 버전을 보려면 파드를 삭제하고 다시 생성해야 합니다. 변경 사항이 있을 때마다 파드를 삭제하는 대신에 볼륨이 항상 깃 리포지터리와 동기화하도록 추가 프로세스를 실행할 수도 있습니다. 이 업계로 들어온다면 점차 깃허브와 친해질 것입니다. 때문에 자주 연습하고 친해지는 것이 좋습니다. 다음은 고려 해 볼 수 있는 사항들을 정리했습니다.
사이드카 컨테이너
깃 동기화 프로세스가 Nginx 웹 서버와 동일 컨테이너에서 실행되면 안 되며 두 번째 컨 테이너인 사이드카(sidecar) 컨테이너에서 실행돼야 합니다. 사이드카 컨테이너는 파드의 주 컨 테이너의 동작을 보완합니다. 새로운 로직을 메인 애플리케이션 코드에 밀어 넣어 복잡성을 더하고 재사용성을 떨어뜨리지만, 파드에 사이드카를 추가하면 기존 컨테이너 이미지를 사용도 있고 로직도 적용할 수 있습니다.
로컬 디렉터리를 깃 리포지터리와 동기화되도록 유지하는 기존의 컨테이너 이미지를 찾으려면 도커 허브로 가서 "git sync"로 검색해보면, 이런 동작을 하는 많은 이미지를 찾 을 수 있습니다. 예제의 파드에서 새 컨테이너에 그 이미지를 사용하고 기존 gitRepo 볼륨을 새 컨테이너에 마운트한 뒤, 깃 동기화 컨테이너가 깃 리포지터리와 파일 동기화를 유지하 도록 설정합니다. 모든 것이 올바르게 설정됐다면 웹 서버가 서비스하는 파일이 항상 깃허브 리포지터리와 동기화될 것입니다.
프라이빗 깃 리포지터리로 gitRepo 볼륨 사용
깃 동기화 사이드카 컨테이너를 사용해야 하는 또 다른 이유가 있습니다. 프라이빗 깃 리포지터 리로 gitRepo 볼륨을 사용할 수 없습니다. 쿠버네티스 개발자들의 공통된 결론은 gitRepo 볼륨을 단순하게 유지하고 프라이빗 리포지터 리를 SSH 프로토콜을 통해 복제하는 방식의 지원을 추가하지 않은 것입니다. gitRepo 볼륨 에 추가 설정 옵션을 필요로 하기 때문입니다.
프라이빗 깃 리포지터리를 컨테이너에 복제하려면 깃 동기화 사이드카나 아니면 git Repo 볼륨을 대신하는 다른 유사 방법을 사용해야 합니다.
쿠버네티스 볼륨은 파드의 구성 요소로 컨테이너와 동일하게 파드 스펙에서 정의됩니다. 볼륨은 독립적인 쿠버네티스 오브젝트가 아니므로 자체적으로 생성, 삭제될 수 없습니다. 볼륨은 파드의 모든 컨테이너에서 사용 가능하지만 접근하려는 컨테이너에서 각각 마운트돼야 합니다. 각 컨테이너에서 파일시스템의 어느 경로에나 볼륨을 마운트 할 수 있습니다.
먼저 다음 그림 A를 통해 설명해 보겠습니다. 컨테이너 세 개가 있는 파드를 가정해 봅시다. 첫 번째 컨테이너는 /var/htdocs 디렉터리에서 HTML 페이지를 서비스하고 /var/logs에 액세스 로그를 저장하는 웹 서버를 실행합니다. 두 번째 컨테이너는 /var/html에 HTML 파일을 생성하는 에이전트를 실행하고, 세 번째 컨테이너는 /var/logs 디렉터리의 로그를 처리합니다.
각 컨테이너는 잘 정의된 단일 책임을 갖고 있지만 각각 컨테이너 자체만으로는 큰 쓸모가 없습니다. 콘텐츠 생성기는 생성한 HTML 파일을 자체 컨테이너 내에 저장하고, 웹 서버는 별도의 분리된 컨테이너에서 실행되므로 이 파일에 접근할 수 없기 때문에 세 컨테이너간에 디스크 스토리지를 공유하지 않는 파드를 생성하는 것은 의미가 없습니다.
파일을 공유하는 대신 웹 서버는 컨테이너 이미지안의 빈 디렉터리나 여러분이 /var/htdocs 디렉터리에 넣은 파일을 서비스할 수 있습니다. 비슷하게 로그 순환기도 /var/logs 디렉터리가 항상 비어있고 아무것도 로그를 쓰지 않기 때문에 아무런 일을 하지 않게됩니다. 이런 세 개의 컨테이너 구성에 볼륨이 없다면 파드는 아무런 동작을 하지 않습니다.
그러나 볼륨 두 개를 파드에 추가하고 세 개의 컨테이너 내부의 적절한 경로에 마운트 한다면 다음 그림와 같이 부분의 합보다 더 나은 시스템이 생성됩니다.
리눅스에서는 파일시스템을 파일 트리의 임의 경로에 마운트할 수 있습니다. 이렇게 하면 마운트된 파일 시스템의 내용은 마운트된 디렉터리에서 접근이 가능합니다. 같은 볼륨을 두 개의 컨테이너에 마운트하면 컨테이너는 동일한 파일로 동작할 수 있습니다. 이 경우 볼륨 두 개를 컨테이너 세 개에 마운트합니다. 이렇게 함으로써 컨테이너 세 개는 함께 동작할 수 있고 유용한 작업을 수행합니다.
이제 동작하는 방법을 알아보겠습니다. 먼저 파드에는 publicHTML이라는 볼륨이 있습니다. 이 볼륨은 WebServer 컨테이너의 /var/htdocs에 마운트됐고 웹 서버는 이 디렉터리의 파일을 서비스합니다. 동일 볼륨이 ContentAgent 컨테이너에 /var/html에 다른 경로로 마운트돼 있고, 콘텐츠 에이전트는 생성된 파일을 해당 경로에 쓰게 됩니다. 이 단일 볼륨을 이런 방식으로 마운트하면 콘텐츠 생성기가 작성한 내용을 웹 서버가 서비스할 수 있게 됩니다.
비슷하게 파드는 로그를 저장하는 logVol 볼륨이 가져갑니다. 이 볼륨은 WebServer와 LogRotator 컨테이너의 /var/logs에 마운트 됩니다. 이 볼륨은 ContentAgent 컨테이너에는 마운트되지 않습니다. 컨테이너와 볼륨이 같은 파드에서 구성됐더라도 컨테이너는 그 파일에 접근할 수 없습니다. 컨테이너에서 접근하려면 파드에서 볼륨을 정의하는 것만으로는 충분하지 않고 VolumeMount를 컨테이너 스펙에 정의해야 합니다.
이 예제의 두 볼륨은 빈 상태로 초기화되므로 emptyDir 유형의 볼륨을 사용할 수 있습니다. 쿠버네티스는 볼륨을 초기화하며 외부 소스의 내용을 채우거나, 볼륨 내부에 기존에 존재하는 디렉터리를 마운트하는 것과 같은 다른 유형의 볼륨도 지원합니다. 볼륨을 채우거나 마운트하는 프로세스는 파드의 컨테이너가 시작되 전에 수행됩니다.
볼륨이 파드의 라이프사이클에 바인딩되면 파드가 존재하는 동안 유지될 수 있지만 볼륨 유형에 따라 파드와 볼륨이 사라진 후에도 볼륨의 파일이 유지돼 새로운 볼륨으로 마운트될 수 있습니다.
볼륨 유형
다양한 유형의 볼륨이 사용이 가능한데 일반적인 것도 있지만, 실제 스토리지 기술에 특화된 것들도 있습니다. 이런 기술을 들어보지 못했다고 하더라도 이상하다고 느낄필요 없는 것이 보통은 이렇게 다양하게 알기보다는 이미 알고 사용했던 기술의 볼륨 유형에 대해서만 알고 사용한다고 합니다. 이제 몇가지 유형을 알아보겠습니다.
emptyDir 일시적인 데이터를 저장하는 데 사용되는 간단한 빈 디렉터리
hostPath 워커 노드의 파일시스템을 파드의 디렉터리로 마운트하는 데 사용
gitRepo 깃 리포지터리의 콘덴츠를 체크아웃해 초기화한 볼륨
nfs NFS 공유를 파드에 마운트합니다.
gcePersistentDisk(Google), awsElasticBlockStore(Amazon), azureDisk(Microsoft) 클라우드 제공자의 전용 스토리지를 마운트하는데 사용
cinder, cephfs, iscsi, flocker, glusterfs, quobyte, rbd, flexVolume, vsphere, Volume, photonPersistentDisk, scaleIO 다른 유형의 네트워크 스토리지를 마운트하는 데 사용
configMap, secret, downwardAPI 쿠버네티스 리소스나 클러스터 정보를 파등 노출하는 데 사용되는 특별한 유형의 볼륨
persistentVolumeClaim 사전에 혹은 동적으로 프로비저닝된 퍼시스텀트 스토리지를 사용하는 방법
볼륨 유형은 다양한 목적을 위해 사용됩니다. 다음 포스팅에서 이 중 몇 가지를 다뤄보도록 하겠습니다. 특수한 유형의 볼륨은 데이터를 저장하는 데 사용되지 않고 쿠버네티스 메타데이터를 파드에 실행 중인 애플리케이션에 노출하는 데 사용되는데 이 내용은 볼륨 유형을 다룬 후에 자세히 알아보도록 하겠습니다.
원래는 바로 다음 내용까지 진행하려 했으나 분량 조절이 쉽지 않아 이번 포스팅은 쉬어가는 느낌으로 볼륨에 대해 소개하고 다음 포스팅부터 제대로 들어가도록 하겠습니다.
Kubernetes의 헤드리스 서비스는 클러스터 IP가 할당되지 않은 특수한 유형의 서비스입니다. 대신 서비스 뒤의 개별 포드를 직접 검색하고 연결하는 방법을 제공합니다. 헤드리스 서비스는 부하 분산이나 서비스에 대한 단일 IP 주소에 의존하지 않고 클라이언트와 포드 간에 직접 연결을 설정해야 하는 경우에 유용합니다. 이는 안정적인 네트워크 ID가 필요한 분산 시스템 또는 상태 저장 애플리케이션과 같은 경우에 유용할 수 있습니다.
헤드 리스 서비스로 개별 파드를 찾기 위해서는 먼저 클라이언트가 모든 파드에 연결을 할 수 있어야 합니다. 클라이언트가 모든 파드에 연결하기 위해서는 각 파드의 IP를 알아야하고, 그 중 한 가지 옵션은 클라이언트가 쿠버네티스 API 서버를 호출해 파드와 IP 주소 목록을 가져오도록 하는 것인데, 애플리케이션을 쿠버네티스와 무관하게 유지하려고 노력해야 하기 때문에 항상 API 서버를 사용하는 것은 바람직하지 않습니다.
다행히 쿠버네티스는 클라이언트가 DNS 조회로 파드 IP를 찾을 수 있도록 합니다. 일반적으로 서비스에 대한 DNS 조회를 수행하면 DNS 서버는 하나의 IP를 반환합니다. 그러나 쿠버네티스 서비스에 클러스터 IP가 필요하지 않다면 DNS 서버는 하나의 서비스 IP 대신 파드 IP들을 반환합니다.
DNS 서버는 하나의 DNS A 레코드를 반환하는 대신 서비스에 대한 여러 개의 A 레코드를 반환합니다. 각 레코드는 해당 시점에 서비스를 지원하는 개별 파드의 IP를 가리킵니다. 따라서 클라이언트는 간단한 DNS A 레코드 조회를 수행하고 서비스에 포함된 모든 파드의 IP를 얻을 수 있습니다. 그런 다음 클라이언트는 해당 정보를 사용해 하나 혹은 다수의 또는 모든 파드에 연결할 수 있습니다.
헤드리스 서비스 생성
서비스 스펙의 clusterIP 필드를 None으로 설정하면 쿠버네티스는 클라이언트가 서비스의 파드에 연결할 수 있는 클러스터 IP를 할당하지 않기 때문에 서비스가 헤드리스 상태가됩니다.
apiVersion: v1 kind: Service metadata: name: kubia-headless spec: clusterIP: None > 이 부분이 있어야 서비스를 헤드리스 서비스로 만듭니다. ports: - port: 80 tragetPort: 8080 selector: app: kubia
kubectl create로 서비스 생성 후 kubectl get과 kubectl describe로 서비스를 살펴볼 수 있습니다. 클러스터 IP가 없고 엔드포인트에 파드 셀렉터와 일치하는 파드가 포함돼 있음을 알 수 있습니다. 파드에 레디니스 프로브가 포함돼 있기 때문에 준비된 파드만 서비스의 엔드포인트로 조회됩니다.
DNS로 파드 찾기
파드가 준비되면 DNS 조회로 실제 파드 IP를 얻을 수 있는지 확인할 수 있습니다. 이 때 파드 내부에서 조회해야 합니다. 안타깝게도 kubia 컨테이너 이미지에는 nslookup 바이너리가 포함돼 있지 않으므로 DNS 조회를 수행하는 데 사용할 수 없습니다.
따라서 필요한 바이너리가 포함된 이미지를 기반으로 새 파드를 실행하면 DNS 관련 작업을 수행하려면 도커 허브의 nslookup 및 dig 바이너리를 모두 포함하는 tutum/dnsutuls 컨테이너 이미지를 사용하면 좋습니다.
파드를 실행하려면 YAML 매니페스트를 만들어 kubectl create로 전달하는 전체 프로세스를 수행할 수 있지만 지나치게 많은 작업이 필요합니다. 때문에 다음 방법을 이용할 수 있습니다. 이 방법으로 진행하면 파드를 관리하는 레플리케이션 컨트롤러를 만들 필요 없이 바로 파드만 만들 수 있습니다.
kubectl run dnsutils --image=tutum/dnsuitls --generator-run-pod/v1 --command -- sleep infinity
트릭은 --generator-run-pod/v1 옵션에 있고, kubectl은 어떤 종류의 레플리케이션컨트롤러나 그와 유사한 장치 없이 파드를 직접 생성하도록 지시합니다. 이제 다음 명령어를 사용해 새 파드로 DNS를 조회할 수 있습니다.
kubectl exec dnsutils nslookup kubia-headless
DNS 서버는 kubia-headless.default.svc.cluster.local FQDN에 대해 서로 다른 두 개의 IP를 반환할 것입니다. 바로 준비됐다고 보고된 파드 두 개의 IP입니다. kubectl get pods -o wide로 파드를 조회하면 이를 확인할 수 있는데, 이것은 파드의 IP를 보여줍니다.
이는 kubia 서비스와 같이 일반 서비스를 DNS가 반환하는 것과는 다릅니다. 반환된 IP는 서비시스의 클러스터 IP 입니다.
kubectl exec dnsutils nslookup kubia
헤드리스 서비스는 일반 서비스와 다르게 보일 수 있지만 클라이언트의 관점에서는 다르지 않습니다. 헤드리스 서비스르 사용하더라도 클라이언트는 일반 서비스와 마찬가지로 서비스의 DNS 이름에 연결해 파드에 연결할 수 있습니다. 그러나 헤드리스 서비스에서는 DNS가 파드의 IP를 반환하기 때문에 클라이언트는 서비스 프록시 대신 파드에 직접 연결합니다.
서비스 문제
서비스는 쿠버네티스에서 정말 중요한 개념이고 많은 개발자가 좌절하는 이유기도 합니다. 많은 개발자들이 서비스 IP 또는 FQDN으로 파드에 연결할 수 없는 이유를 파악하는 데 많은 시간을 허비하는 경우가 꾀 많았습니다. 이런 이유로 서비스 문제 해결법을 간략히 살펴보려 합니다. 서비스로 파드에 액세스할 수 없는 경우 다음과 같은 내용을 확인후 다시 시작해봅시다.
먼저 외부가 아닌 클러스터 내에서 서비스의 클러스터 IP에 연결되는지 확인합니다.
서비스에 액세스할 수 있는지 확인하려고 서비스 IP로 핑을 할 필요 없습니다. 서비스의 클러스터 IP는 가상 IP이기 때문입니다.
레디니스 프로브를 정의했다면 성공했는지 확인합니다. 그렇지 않으면 파드는 서비스에 포함되지 않습니다.
파드가 서비스의 일부인지 확인하려면 kubectl get endpoints를 사용해 해당 엔드포인트 오브젝트를 확인합니다.
FQDN이나 그 일부로 서비스에 액세스하려고 하는데 작동하지 않는 경우, FQDN 대신 클러스터 IP를 사용해 액세스할 수 있는지 확인합니다.
대상 포트가 아닌 서비스로 노출된 포트에 연결하고 있는지 확인합니다.
파드 IP에 직접 연결해 파드가 올바른 포트에 연결되어 있는지 확인합니다.
파드 IP로 애플리케이션에 액세스할 수 없는 경우 애플리케이션이 로컬호스트에만 바인딩하고 있는지 확인합니다.
이 내용은 서비스 관련된 많은 부분의 문제를 해결하는 데 도움이 될 것입니다. 나중에 서비스 동작 방식을 더 깊이 다뤄보려하는데 구현 방식을 정확히 이해하면 서비스 문제를 해결하기 훨씬 쉬워질 것입니다.
이제 서비스의 남은 부분은 잠시 뒤로 넘겨두고 스토리지와 볼륨에 대해 다뤄보려고 합니다. 뒤로 갈수록 점점 어려워짐에 따라 포스팅 시간도 늘어나 공부가 쉽지 않네요. 쿠버네티스를 정리하는 과정은 이제 약 25%정도가 다루었습니다. 이제 에티버스러닝에서도 쿠버네티스는 끝났고 vSphere에 대해 다루기 시작했는데 이것도 정리하려고 하면 수일이 걸릴거 같아 벌써 앞이 깜깜하네요.
이제 곧 2달이 되어가는데, 항상 느끼는 것은 네트워크도 그렇고 리눅스도 그렇고 어떻게 한번에 되는게 거의 없는지 처음에는 많이 답답했는데, 이제는 오류가 안나오면 그게 더 이상합니다. 최근 재해 복구 솔루션에 대해 뉴스에서 많이 언급되고 있는데, 그 이유에 대해서 조금은 알 것 같기도 합니다. 똑같이 했는데도 어디선가 오류가 나오고 틀어져, 물리적으로 피해를 입는 것이 아니더라도 온전히 서비스하는 것은 쉽지 않겠구나 생각이 듭니다.
현직자이신 강사님들(현직에 종사하면서 회사차원에서 강의하러 오시는 강사님들도 계십니다.)께서도 강의 중 발생한 문제 때문에 트러블슈팅하느라 진땀빼는 일이 비일비재하니 실제로 서비스를 하게 된다면 말 다했죠. 이렇게 돌아보면 힘들긴 했지만 또 이 상황이 웃기기도 합니다.
IT에서 취업을 준비하시는 분, 개인적으로 공부하시는 분들 노력 하나하나가 내용을 알면 알수록 점점 크고 대단하게 느껴집니다. 한 걸음 다가가면 5걸음은 멀어지는 느낌이라 힘들지만 언제가는 뛰어갈 수 있도록 노력해야겠죠? 저도 얼른 걸음마에 적응하고 뛸 준비를 할 수 있도록 코어를 키워봐야겠습니다. 끝까지 읽어주셔서 감사하고 여러분들께 항상 행운이 가득하길 소망해보겠습니다.
파드의 레이블이 서비스의 파드 셀렉터와 일치할 경우 파드가 서비스의 엔드포인트에 포함됩니다. 적절한 레이블을 가진 새 파드가 만들어지자마자 서비스의 일부가 돼 요청이 파드로 전달되기 시작합니다. 하지만 만약 그 파드가 즉시 요청을 처리할 준비가 돼 있지 않다면 어떻게 될까요?
파드는 구성에 시간이 걸리거나 데이터를 로드하는 데 시간이 필요할 수 있고, 첫 번째 사용자 요청이 너무 오래 걸리거나 사용자 경험에 영향을 미치는 것을 방지하고자 준비 절차를 수행해야 할 수도 있습니다. 이러한 경우 특히 이미 실행 중인 인스턴스가 요청을 적절하고 신속하게 처리할 수 있는 경우 파드가 요청을 즉시 받기 시작하는 것을 원하지 않을 수 있습니다. 완전히 준비될 때까지 기동 중인 파드에 요청을 전달하지 않는 것이 좋습니다.
레디니스 프로브
이전에 다루었던 라이브니스 프로브와 불안전한 컨테이너를 자동으로 다시 시작해 애플리케이션의 상태를 원활히 유지하는 방법을 배웠습니다. 쿠버네티스에서는 라이브니스 프로브와 비슷하게 파드에 레디니스 프로브(readiness probe)를 정의할 수 있습니다.
레디니스 프로브는 주기적으로 호출되며 특정 파드가 클라이언트 요청을 수신할 수 있는지를 결정합니다. 컨테이너의 레디니스 프로브가 성공을 반환하면 컨테이너가 요청을 수락할 준비가 됐다는 신호입니다.
준비가 됐다(being ready)라는 표시는 분명 각 컨테이너마다 다를 수 있습니다. 쿠버네티스는 컨테이너에서 실행되는 애플리케이션이 간단한 GET / 요청에 응답하는지 혹은 특정 URL 경로를 호출할 수 있는지 확인하거나 필요에 따라 애플리케이션이 준비됐는지 확인하기 위해 전체적인 항목을 검사하기도 합니다. 애플리케이션 특성에 따라 상세한 레디니스 프로브를 작성하는 것은 애플리케이션 개발자의 몫입니다.
레디니스 프로브 유형
라이브니스 프로브와 마찬가지로 세 가지 유형의 레디니스 프로브가 존재합니다.
Exec 프로브 컨테이너의 상태를 프로세스의 종료 상태 코드로 결정합니다.
HTTP GET 프로브 HTTP GET 요청을 컨테이너로 보내고 응답의 HTTP 상태 코드를 보고 컨테이너가 준비됐는지 여부를 결정합니다.
TCP 소켓 프로브 컨테이너의 지정된 포트로 TCP 연결을 엽니다. 소켓이 연결되면 컨테이너가 준비된 것으로 간주합니다.
레디니스 프로브의 동작
컨테이너가 시작될 때 쿠버네티스는 첫 번째 레디니스 점검을 수행하기 전에 구성 가능한 시간이 경과하기를 기다리도록 구성할 수 있습니다. 그런 다음 주기적으로 프로브를 호출하고 레디니스 프로브의 결과에 따라 작동합니다. 파드가 준비되지 않았다고 하면 서비스에서 제거됩니다. 파드가 다시 준비되면 서비스에 다시 추가됩니다.
라이브니스 프로브와 달리 컨테이너가 준비 상태 점검에 실패하더라도 컨테이너가 종료되거나 다시 시작되지 않습니다. 이는 라이브니스 프로브와 레디니스 프로브 사이의 중요한 차이입니다. 라이브니스 프로브는 상태가 좋지 않은 컨테이너를 제거하고 새롭고 건강한 컨테이너로 교체해 파드의 상태를 정상으로 유지하는 반면, 레디니스 프로브는 요청을 처리할 준비가 된 파드의 컨테이너만 요청을 수신하도록 합니다. 이것은 컨테이너를 시작할 때 주로 필요하지만 컨테이너가 작동한 후에도 유용합니다.
다음 그림에서 볼 수 있듯이 레디니스 프로브가 실패하면 파드는 엔드포인트 오브젝트에서 제거됩니다. 서비스로 연결하는 클라이언트의 요청은 파드로 전달되지 않습니다. 파드의 레이블이 서비스의 레이블 셀렉터와 일치하지 않을 때와 같은 효과입니다.
레디니스 프로브가 중요한 이유
파드 그룹이 다른 파드에서 제공하는 서비스에 의존한다고 가정해봅시다. 프론트엔드 파드 중 하나에 연결 문제가 발생해 더 이상 데이터베이스에 연결할 수 없는 경우, 해당 시점에 파드가 해당 요청을 처리할 준비가 되지 않았다는 신호를 레디니스 프로브가 쿠버네티스에게 알리는 것이 현명할 수 있습니다.
다른 파드 인스턴스에 동일한 유형의 연결 문제가 발생하지 않는다면 정상적으로 요청을 처리할 수 있습니다. 레디니스 프로브를 사용하면 클라이언트가 정상 상태인 파드하고만 통신하고 시스템에 문제가 있다는 것을 절대 알아차릴 수 없습니다.
즉, 레디니스 프로브가 제대로 구성되어 있지 않으면, 클라이언트는 문제가 있는 파드와도 통신을 시도하고, 이로 인해 시스템 장애가 발생할 수 있습니다. 따라서 레디니스 프로브를 올바르게 구성하는 것이 중요합니다.
파드에 레디니스 프로브 추가
kubectl edit 명령어로 기존 레플리케이션 컨트롤러의 파드 템플릿에 프로브를 추가할 수 있습니다.
kubectl edit rc kubia
텍스트를 편집기에서 레플리케이션 컨트롤러 YAML이 열리면 파드 템플릿에 컨테이너 스펙을 찾고 spec.tamplate.spec.containers 아래의 첫 번째 컨테이너에 다음 레디니스 프로브 스펙을 추가합니다.
... spec: ... template: ... spec: containers: - name: kubia image: luksa/kubia readinessProbe: > 파드의 각 컨테이너에 레디니스 프로브가 이런 방식으로 정의될 수 있습니다. exec: command: - ls - /var/ready ...
레디니스 프로브는 컨테이너 내부에서 ls /var/ready 명령어를 주기적으로 수행합니다. ls 명령어는 파일이 존재하는 종료 코드 0을 반환하고 그렇지 않으면 0이 아닌 값을 반환합니다. 파일이 있으면 레디니스 프로브가 성공하고 그렇지 않으면 실패합니다.
다소 이상할 수 있는 레디니스 프로브를 정의하는 이유는 문제의 파일을 생성하거나 제거해 그 결과를 바로 전환할 수 있기 때문입니다. 아직 파일이 없으므로 모든 파드가 준비되지 않았다고 보고해야 합니다. 그렇다고 무조건 그런 것은 아닙니다. 레플리케이션 컨트롤러에 대해 다룰 때에도 파드 템플릿을 변경해도 기존 파드에는 영향을 미치지 않습니다.
즉, 기존 파드는 여전히 레디니스 프로브가 정의돼 있지 않습니다. kubectl get pods로 파드를 조회하고 READY 열을 보면 확인할 수 있습니다. 파드를 삭제하면 레플리케이션 컨트롤러가 다시 파드를 생성합니다. 새 파드는 레디니스 점검에 실패하고 각각에 /var/ready 파일을 만들 때까지 서비스의 엔드포인트에 포함되지 않을 것입니다.
실제 환경에서 수행해야 하는 기능
실제 환경에서 레디니스 프로브는 애플리케이션이 클라이언트 요청을 수신할 수 있는지 여부에 따라 성공 또는 실패를 반환해야 합니다.
서비스에서 파드를 수동으로 제거하려면 수동으로 프로브의 스위치를 전환하는 대신 파드를 삭제하거나 파드 레이블을 변경해야 합니다. 수동으로 추가 및 제거를 한다면 파드와 서비스의 레이블 셀렉터에 enabled=ture 부분을 추가하면 생성되고 레이블을 제거하면 서비스에서 파드도 제거됩니다.
레디니스 프로브에서 알야할 2가지에 대해 알아보겠습니다.
레디니스 프로브를 항성 정의
파드에 레디니스 프로브를 추가하지 않으면 파드가 시작하는 즉시 서비스 엔드포인트가 됩니다. 애플리케이션이 수신 연결을 시작하는 데 너무 오래 걸리는 경우 클라이언트의 서비스 요청은 여전히 시작 단계로 수신 연결을 숫락할 준비가 되지 않은 상태에서 파드로 전달됩니다. 따라서 클라이언트는 "Connection refused" 유형의 에러를 보게 될 것입니다. 기본 URL에 HTTP 요청을 보내더라도 항상 레디니스 프로브를 정의하는 습관을 들여야합니다.
레디니스 프로브에 파드의 종료 코드를 포함하지 않기
나머지 강조할 점은 파드의 라이프 사이클 마지막 단계에서 고려해야 하며 연결 오류가 발생한 클라이언트와 관련된 내용입니다. 파드가 종료할 때, 실행되는 애플리케이션은 종료 신호를 받자마자 연결 수락을 중단합니다. 그렇기 때문에 종료 절차가 시작되는 즉시 레디니스 프로브가 실행하도록 만들어 파드가 모든 서비스에서 확실하게 제거돼야 한다고 생각할 수 있습니다. 하지만 그건 필요하지 않습니다. 쿠버네티스는 파드를 삭제하자마자 모든 서비스에서 파드를 제거하기 때문입니다.
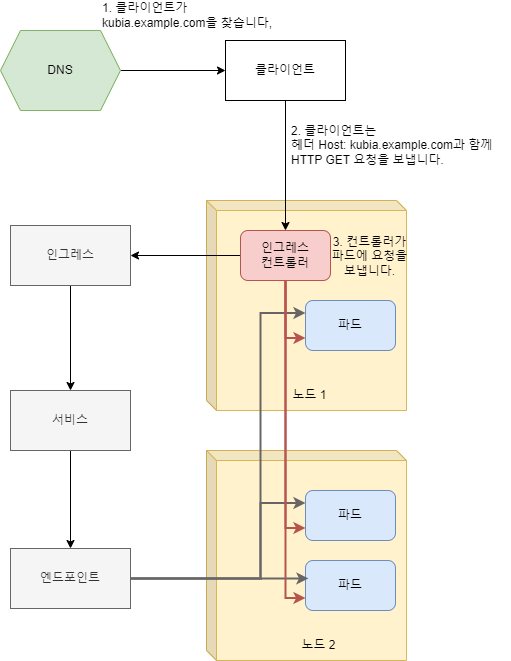
로드밸런서 서비스는 자신의 공용 IP 주소를 가진 로드밸런서가 필요하지만, Ingress는 한 IP 주소로 수십 개의 서비스에 접근이 가능하도록 지원해줍니다. 클라이언트가 HTTP 요청을 Ingress에 보낼 때, 요청한 호스트와 경로에 따라 요청을 전달할 서비스가 결정됩니다. 이는 다음 그림을 참고할 수 있습니다.
Ingress는 네트워크 스택의 애플리케이션 계층(HTTP, OSI 7계층 중 7계층에 해당)에서 작동하며 서비스가 할 수 없는 쿠키 기반 세션 어피니티 등과 같은 기능을 제공할 수 있습니다.
Ingress 오브젝트가 제공하는 기능을 살펴보기 전에 Ingress 리소스를 작동시키려면 클러스터에 Ingress 컨트롤러를 실행해야 합니다. 쿠버네티스 환경마다 다른 컨트롤러 구현을 사용할 수 있지만 일부는 기본 컨트롤러를 전혀 제공하지 않습니다.
예를 들어 구글 쿠버네티스 엔진은 구글 클라우드 플랫폼의 고유한 HTTP 로드 밸런싱 기능을 사용해 Ingress 기능을 제공합니다. 초기에 minikube는 기본 Ingress 컨트롤러를 제공하지 않았지만 이제 Ingress 기능을 시험해볼 수 잇는 애드온을 제공합니다.
Ingress 리소스 생성
클러스터에서 Ingress 컨트롤러가 실행 중인 것을 확인했다면 이제 Ingress 리소스를 만들 수 있습니다. 다음 예제는 Ingress에 대한 YAML 매니페스트를 보여줍니다.
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: kubia spec: rules: - host: kubia.example.com > Ingress는 kubia.example.com 도메인 이름을 서비스에 매핑합니다. http: paths: - path: / > 모든 요청은 kubia-nodeport 서비스 포트인 80으로 전달됩니다. backend: serviceName: kubia-nodeport servicePort: 80
Host kubia.examle.com으로 요청되는 Ingress 컨트롤러에 수신된 모든 HTTP 요청을 포트 80의 kubia-nodeport 서비스로 전송하도록 하는 Ingress 규칙을 정의한 것입니다. 참고로 GKE와 같은 클라우드 공급자의 Ingress 컨트롤러는 Ingress가 노드포트 서비스를 가리킬 것을 요구합니다. 하지만 그것이 쿠버네티스 자체의 요구 사항은 아닙니다.
Ingress로 서비스 엑세스
http://kubia.example.com 서비스에 액세스하려면 도메인 이름이 Ingress 컨트롤러의 IP와 매핑되도록 확인해야 합니다.
Ingress의 IP 주소 를 확인하려면 Ingress 목록을 확인해야 합니다. kubectl get ingresses 명령어로 목록을 확인할 수 있습니다. 만약 클라우드에서 실행하는 경우 Ingress 컨트롤러가 뒷단에서 로드밸런서를 프로비저닝하기 때문에 주소가 표시되는데 시간이 조금 걸릴 수 있습니다. 명령어 결과가 출력되면 IP는 ADDRESS 열에 표시됩니다.
Ingress 컨트롤러가 구성된 호스트의 IP를 Ingress 엔드포인트로 지정할 수 있는데, 방금 설명한 방법으로 IP를 알고 나면 kubia.example.com을 해당 IP로 확인하도록 DNS 서버를 구성하거나, 다음 줄을 /etc/hosts에 추가하여 지정할 수 있습니다.
이제 Ingress로 파드에 엑세스하기 위한 모든 것이 설정됐으므로 브라우저 또는 curl을 통해 http://kubia.example.com 서비스에 엑세스할 수 있습니다.
Ingress 동작 방식
다음 그림은 클라이언트가 Ingress 컨트롤러로 파드에 연결하는 방식을 보여줍니다. 클라이언트는 먼저 kubia.example.com의 DNS 조회를 수행했으며 DNS 서버(또는 로컬 운영 체제)가 Ingress 컨트롤러의 IP를 반환합니다. 그런 다음 클라이언트는 HTTTP 요청을 Ingress 컨트롤러로 전송하고 host 해더에서 kubia.example.com을 지정합니다. 컨트롤러는 해당 해더에서 클라이언트가 액세스하려는 서비스를 결정하고 서비스와 관려된 엔드포인트 오브젝트로 파드 IP를 조회한 다음 클라이언트 요청을 파드에 전달합니다.
보다시피 Ingress 컨트롤러는 요청을 서비스로 전달하지 않습니다. 파드를 선택하는 데만 사용합니다. 모두는 아니지만 대부분의 컨트롤러는 이와 같이 동작합니다.
하나의 Ingress로 여러 서비스 노출
Ingress 스펙을 자세히 보면 규칙과 경로가 모두 배열이므로 여러 항목을 가질 수 있습니다. Ingress는 다음에서 볼 수 있듯이 여러 호스트와 경로를 여러 서비스에 매핑할 수있습니다.
1. 동일한 호스트의 다른 경로로 여러 서비스 매핑
다음 예제에 표시된 것처럼 동일한 호스트의 여러 경로를 다른 서비스에 매핑할 수 있습니다.
컨트롤러가 수신한 요청은 요청의 호스트 헤더(웹 서버에서 가상 호스트가 처리되는 방식)에 따라 서비스 foo 또는 bar로 전달됩니다. DNS는 foo.example.com과 bar.example.com 도메인 이름을 모두 Ingress 컨트롤러의 IP 주소로 지정해야 합니다.
TLS TLS 트레픽을 처리하도록 Ingress 구성
Ingress를 위한 TLS 인증서 생성
클라이언트가 Ingress 컨트롤러에 대한 TLS 연결을 하면 컨트롤러는 TLS 연결을 종료합니다. 클라이언트와 컨트롤러 간의 통신은 암호화되지만 컨트롤러와 백엔드 파드 간의 통신은 암호화되지 않습니다. 파드에서 실행 중인 애플리케이션은 TLS를 지원할 필요가 없습니다.
예를 들어 파드가 웹 서버를 실행하는 경우 HTTP 트래픽만 허용하고 Ingress 컨트롤러가 TLS와 관련된 모든 것을 처리하도록 할 수 있습니다. 컨트롤러가 그렇게 하려면 인증서와 개인 키를 Ingress에 첨부해야 합니다. 이 두개는 시크릿 이라는 쿠버네티스 리소스에 저장하면 Ingress 매니페스트에서 참조합니다. 이 시크릿은 다음에 자세히 다뤄보도록 하겠습니다.
참고로 Ingress를 삭제하고 다시 만드는 대신 kubectl apply -f 명령어로 위 YAML을 사용하면 파일에 지정된 내용으로 Ingress 리소스가 업데이트됩니다.
이제 HTTPS로 Ingress를 통해 서비스에 액세스할 수 있습니다.
curl -k -v https://kubia.example.com/kubia
명령어의 출력에는 애플리케이션의 응답과 Ingress에 구성한 서버 인증서가 표시 됩니다. Ingress 기능에 대한 지원은 Ingress 컨트롤러 구현마다 서로 다르므로 관련 문서에서 지원 내용을 확인할 필요가 있습니다.
TLS?
TLS(Transport Layer Security, 전송 계층 보안)는 클라이언트와 서버 간의 네트워크 통신을 보호하는 데 사용되는 암호화 프로토콜입니다. 쿠버네티스의 맥락에서 TLS는 클러스터 내에서 실행되는 클라이언트와 서비스 간 또는 쿠버네티스 컨트롤 플레인의 서로 다른 구성 요소 간 통신 보안과 관련하여 자주 논의됩니다.
다음은 쿠버네티스에서 TLS가 관련된 몇 가지 예입니다.
수신 및 TLS:
Ingress 리소스를 사용하여 외부 트래픽을 쿠버네티스 클러스터 내의 서비스로 라우팅할 때 클라이언트와 Ingress 간의 통신을 암호화하도록 TLS를 구성할 수 있습니다. 이렇게 하면 클라이언트와 서비스 간에 전송되는 데이터가 기밀로 유지되고 도청이나 변조로부터 보호됩니다. Ingress 리소스에서 TLS를 활성화하려면 TLS 인증서와 개인 키가 포함된 TLS 시크릿을 생성한 다음 Ingress 구성에서 이 시크릿을 참조해야 합니다.
쿠버네티스 API 서버 보안:
쿠버네티스 API 서버는 쿠버네티스 API를 노출하는 중앙 구성 요소로, 클러스터와 상호 작용하고 클러스터를 관리할 수 있습니다. API 서버와 클라이언트(예: kubectl, 대시보드) 또는 기타 컨트롤 플레인 구성 요소(예: etcd, kubelet) 간의 통신을 보호하는 데 필수적입니다. TLS는 이 통신을 암호화하는 데 사용되어 교환된 데이터가 기밀로 유지되도록 하고 클라이언트는 API 서버의 신뢰성을 확인할 수 있습니다.
컨트롤 플레인 구성 요소 간의 통신 보안:
API 서버 외에도 etcd 및 kubelet과 같은 쿠버네티스 컨트롤 플레인의 다른 구성 요소도 TLS를 사용하여 통신을 보호합니다. 예를 들어 쿠버네티스의 데이터 저장소인 etcd는 TLS를 사용하여 etcd 피어 간 및 etcd와 API 서버 간 트래픽을 암호화하여 데이터 기밀성과 무결성을 보장합니다.
서비스 간 통신 보안:
경우에 따라 쿠버네티스 클러스터 내의 서비스 간 통신을 보호해야 할 수 있습니다. Istio 또는 Linkerd와 같은 도구를 사용하여 서비스 간 mTLS(상호 TLS)를 자동으로 활성화할 수 있는 서비스 메시를 설정할 수 있습니다. mTLS는 클라이언트와 서버가 서로를 인증하고 통신을 암호화하도록 합니다.