

목차
- 외부 클라이언트에 서비스 노출
- 노드포트
- 노드포트 서비스
- 노드포트 서비스 확인
- 로드벨런서
- 외부 로드 밸런서로 서비스 노출
- 로드밸런서 서비스 생성
- 로드밸런서를 통한 서비스 연결
- 외부 연결 특성
- 불필요한 네트워크 홉
- 클라이언트 IP가 보존되지 않음
외부 클라이언트에 서비스 노출
이번 포스팅에서는 다음 그림과 같이 프론트엔드 웹서버와 같은 특정 서비스를 외부에 노출해 외부 클라이언트가 액세스할 수 있게 하는 방법에 대해 다뤄보도록 하겠습니다.

외부에서 서비스를 액세스할 수 있는 몇 가지 방법이 있습니다.
- 노드포트로 서비스 유형 설정
노드포트(NodePort) 서비스의 경우 각 클러스터 노드는 노드 자체에서 포트를 열고 해당 포트로 수신된 트래픽을 서비스로 전달합니다. 이 서비스는 내부 클러스터 IP와 포트로 액세스할 수 있을 뿐만 아니라 모든 노드의 전용 포트로도 액세스할 수 있습니다. - 서비스 유형을 로드밸런서(노드포트의 확장 버전)로 설정
쿠버네티스가 실행 중인 클라우드 인프라에서 프로비저닝된 전용 로드밸런서(LoadBalancer)로 서비스에 액세스할 수 있습니다. 로드밸런서는 트래픽을 모든 노드의 노드포트로 전달합니다. 클라이언트는 로드밸런서의 IP로 서비스에 액세스합니다. - 단일 IP 주소로 여러 서비스를 노출하는 인그레스 리소스 만들기
HTTP 레벨에서 작동하므로 4계층 서비스보다 더 많은 기능을 제공할 수 있습니다. 이 인그레스 리소스는 다음 포스팅에서 자세히 다뤄보도록 하겠습니다.
노드포트
노드포트 서비스
파드 세트를 외부 클라이언트에 노출시키는 첫 번째 방법은 서비스를 생성하고 유형을 노드포트로 설정하는 것입니다. 노드포트 서비스를 만들면 쿠버네티스는 모든 노드에 특정 포트를 할당하고(모든 노드에서 동일한 포트 번호가 사용됩니다.) 서비스를 구성하는 파드로 들어오는 연결(connection)을 전달(forwarding)합니다.
이것은 일반 서비스와 유사하지만 서비스의 내부 클러스터IP뿐만 아니라 모든 노드의 IP와 할당된 노드 포트로 서비스에 액세스할 수 있습니다. 이것은 노드포트 서비스와 상호작용할 때 더 큰 의미가 부여됩니다.
노드포트 서비스 YAML 생성
apiVersion: v1
kind: Service
metadata:
name: kubia-nodeport
spec:
type: NodePort > 서비스 유형을 node port로 설정합니다.
ports:
- prot: 80 > 서비스 내부 클러스터 IP의 포트
targetPort: 8080 > 서비스 대상 파드의 포트
nodePort: 30123 > 각 클러스터 노드의 포트 30123으로 서비스에 액세스할 수 있습니다.
selector:
app: kubi
유형으르 노드포트로 설정하고 이 서비스가 모든 클러스터 노드에 바인딩돼야 하는 노드 포트를 지정합니다. 노드 포트를 반드시 지정해야 하는것은 아니지만 이를 생략한다면 쿠버네티스가 임의의 포트를 선택할 것입니다. 예를들어 GKE에서 서비스를 만들 때, kubelet은 방화벽 규칙을 설정하라는 내용의 경고를 보여줄 것입니다. 이럴 때 다음과 같은 방법을 진행합니다.
노드포트 서비스 확인
위 YAML을 apply 혹은 create해서 생성했다면 kubectl get svc kubia-nodeport로 해당 서비스의 내용을 확인해볼 수 있습니다. 여기서 3번째 열에 'EXTERNAL-IP'부분을 확인할 수 있을 것입니다. 만약 위 YAML로 잘 생성이 되었다면 해당 부분에 <nodes>라고 표시돼 있고, 이는 클러스터 노드의 IP 주소로 서비스에 엑세스 할 수 있다는 것을 의미합니다. PORT(S) 열에는 클러스터 IP의 내부 포트 (80)과 노드 포트 (30123)이 모두 표시됩니다. 이 서비스는 다음 주소에서 액세스할 수 있습니다.
- <클러스터 IP>:80
- <첫 번째 노드 IP>:30123
- <두 번쨰 노드 IP>:30123 등
다음 그림은 두 클러스터 노드의 포트 30123에 노출된 서비스를 보여줍니다.(GKE에서 이를 실행하면 적용됩니다. minikubve는 단일 노드만을 갖고 있지만 원칙은 동일학 적용됩니다.) 이런 포드에 대한 수신 연결은 임의로 선택된 파드로 전달되며, 연결 중인 노드에서 실행 중인 포트일 수도 있고 아닐 수도 있습니다.
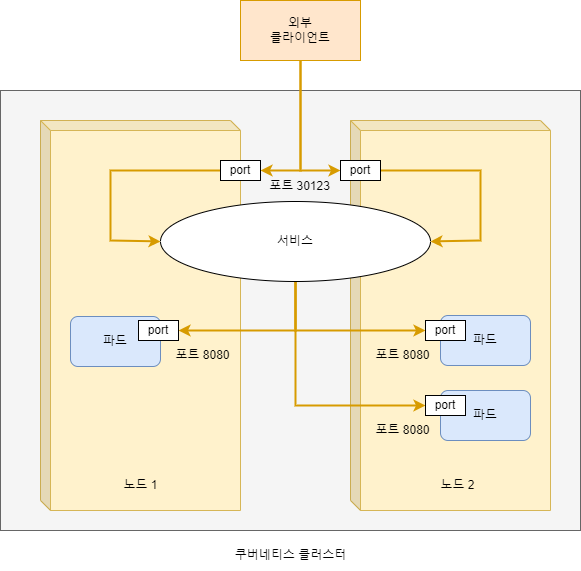
첫 번째 노드의 포트 30123에서 수신된 연결은 첫 번째 노드에서 실행 중인 파드 또는 두 번째 노드에서 실행 중인 파드로 전달할 수 있습니다.
이제 외부 클라이언트가 노드포트 서비스에 액세스할 수 있도록 방화벽 규칙을 변경해줍니다. 앞서 언급했듯이 노드포트로 서비스에 액세스하려면 해당 노드포트에 대한 외부 연결을 허용하도록 구글 클라우드 플랫폼의 방화벽을 구성해야 합니다. 다음 명령어로 작업을 수행할 수 있습니다.
gcloud compute firewall-rules create kubia-svc-rule --allow=tcp:30123
노도 IP와 포트 30123으로 서비스를 액세스할 수 있게 되었습니다. 그러나 먼저 노드 IP를 알아야 합니다. 이 때 kubectl get nodes 명령어를 활용할 수 있습니다. 노드의 IP를 알고 나면 서비스에 curl 명령어를 이용해 서비스에 액세스할 수 있습니다.
이제 인터넷에서 어떤 노드든 포트 30123으로 파드에 액세스할 수 있습니다. 클라이언트가 요청을 보내는 노드는 중요하지 않습니다, 그러나 클라이언트가 첫 번째 노드에만 요청하면 해당 노드가 장애가 나면 클라이언트는 더 이상 서비스에 액세스할 수 없습니다. 그렇기 때문에 모든 노드에 요청을 분산시키고 해당 시점에 오프라인 상태인 노드로 요청을 보내지 않도록 노드 앞에 로드밸런서를 배치하는 것이 좋습니다.
쿠버네티스 클러스터가 이를 지원하는 경우 노드포트 서비스 대신 로드밸런서를 생성해 로드밸런서를 자동으로 프로비저닝 할 수 있습니다.
로드 밸런서
외부 로드 밸런서로 서비스 노출
클라우드 공급자에서 실행되는 쿠버네티스 클러스터는 일반적으로 클라우드 인프라에서 로드밸런서를 자동으로 프로비저닝하는 기능을 제공합니다. 노드 포트 대신 서비스 유형을 로드밸런서로 설정하기만 하면 됩니다. 로드 밸런서는 공개적으로 액세스 가능한 고유한 IP 주소를 가지며 모든 연결을 서비스로 전달합니다. 따라서 로드밸런서의 IP 주소로 서비스에 액세스할 수 있습니다.
쿠버네티스가 로드 밸런서 서비스를 지원하지 않는 환경에서 실행 중인 경우 로드밸런서는 프로비저닝되지 않지만 서비스는 여전히 노드포트 서비스처럼 작동합니다, 로드밸런서 서비스는 노드포트 서비스의 확장이기 때문입니다. 로드밸런서 서비스를 지원하는 구글 쿠버네티스 엔진(GKA)에서 이 예제를 실행할 수 있습니다.
로드밸런서 서비스 생성
앞에서 로드밸런서를 사용해 서비스를 생성하려면 다음 예제와 같이 YAML 매니페스트에 따라 서비스를 생성합니다.
apiVersion: v1
kind: Service
metadata:
nema: kubia-loadbalancer
spec:
type: LoadBalancer > 이 유형의 서비스는 쿠버네티스 클러스터를 호스팅하는 인프라에서
ports: 로드밸런서를 얻을 수 있습니다.
- port: 80
targetPort: 8080
selector:
app: kubia
이 예제에서 서비스 유형은 노드포트 대신 로드밸런서로 설정돼 있습니다. 특정 노드포트를 지정할 수 있지만 지정하지 않았으므로 쿠버네티스가 대신 포트를 자동으로 선택하게 됩니다.
로드밸런서를 통한 서비스 연결
서비스를 생성한 후 클라우드 인프라가 로드밸런서를 생성하고 IP 주소를 서비스 오브젝트에 쓰는 데 시간이 걸립니다. 그것이 완료되면 로드밸런서 IP 주소가 서비스의 external IP 주소로 표시됩니다. 이 서비스를 kubectl get svc 명령어로 확인할 수 있고, 출력되는 EXTERNAL - IP로 curl을 이용해 서비스에 엑세스할 수 있습니다. 이 방법을 통해 노드 포트와는 달리방화벽 설정 없이 연결할 수 있습니다.
파드에 HTTP 요청이 전달되는 방법을 확인하기 위해 다음 그림을 참고할 수 있습니다. 외부 클라이언트는 로드밸런서의 포트 80에 연결하고 노드에 암묵적으로 할당된 노드포트로 라우팅됩니다. 여기에서 연결은 파드 인스턴스로 전달됩니다.

로드 밸런서 유형 서비스는 '추가 인프라 제공 로드밸런서가 있는 노드포트 서비스'입니다. kubectl describe를 사용해 서비스에 대한 추가 정보를 보면 서비스에 노드포트가 선택됐음을 알 수 있습니다. 노드포트 부분에서 수행한 방식으로 노드포트 서비스에 대한 포트의 방화벽을 여는 경우 노드 IP로도 서비스에 액세스할 수 있습니다.
외부 연결 특성
- 불필요한 네트워크 홉
외부 클라이언트가 노드포트로 서비스에 접속할 경우(로드밸런서를 먼저 통과하는 경우도 포함) 임의로 선택된 파드가 연결을 수신한 동일한 노드에서 실행 중일 수도 있고, 그렇지 않을 수 도 있습니다. 파드에 도달하려면 추가적인 네트워크 홉이 필요할 수 있으며 이것이 항상 바람직한것은 아닙니다.
외부의 연결을 수신한 노드에서 실행 중인 파드로만 외부트래픽을 전달하도록 서비스를 구성해 이 추가 홉을 방지할 수 있습니다. 서비스의 스펙 섹션의 externalTrafficPolicy 필드를 생성하는 방법입니다. 위와 같은 YAML 파일 spec: 부분 밑으로 추가해주면 적용됩니다.
서비스 정의에 이 설정이 포함되어 있고 서비스의 노드포트로 외부 연결이 열린 경우 서비스 프록시는 로컬에 실행 중인 파드를 선택합니다. 로컬 파드가 존재하지 않으면 연결이 중단됩니다.(어노테이션을 사용하지 않을 때 연결이 임의의 글로벌 파드로 전달되지 않습니다.) 따라서 로드밸런서는 그러한 파드가 하나 이상 있는 노드에만 연결을 전달하도록 해야 합니다.
이 어노테이션을 사용하면 또 다른 단점이 있습니다. 일반적으로 연결은 모든 파드에 균등하게 분산되지만 이 어노테이션을 사용할 때는 더 이상 적용되지 않습니다.
노드 두 개와 파드 세 개가 있다고 가정해봅시다. 노드 A 가 하나의 파드를 실행하고 노드 B 가 다른 두개를 실행한다고 가정하면 로드 밸런서가 두 노드 걸쳐 연결을 균등하게 분산하면 다음 그림에 표시된 것 처럼 노드 A의 파드는 모든 연결의 50%를 수신하지만 노드 B의 두 파드는 각각 25%만 수신합니다. - 클라이언트 IP가 보존되지 않음
일반적으로 클러스터 내의 클라이언트가 서비스로 연결할 때 서비스의 파드는 클라이언트의 IP 주소를 얻을 수 있습니다. 그러나 노드포트로 연결을 수신하면 패킷에서 소스 네트워크 주소 변환(SNAT)이 수행되므로 패킷의 소스 IP가 변경됩니다.
파드는 실제 클라이언트의 IP를 볼 수 없습니다. 이는 클라이언트의 IP를 알아야 하는 일부 애플리케이션에서 문제가 될 수 있습니다. 예를 들어 웹 서버의 경우 액세스 로그에 브라우저의 IP를 표시하지 못한다는 것을 의미합니다.
이전에 설명한 로컬 외브 트래픽 정책(Local External Traffic Policy)은 연결을 수신하는 노드와 대상 파드를 호스팅하는 노드 사이에 추가 홉이 없기 때문에 클라이언트 IP 보존에 영향을 미친다(SNAT가 수행되지 않습니다.).
'Container > Kubernetes' 카테고리의 다른 글
| [Kubernetes Service] 6. 레디니스 프로브(readyness probe)로 수신 요청 (0) | 2023.04.11 |
|---|---|
| [Kubernetes Service] 5. 인그레스로 통신 및 TLS로 보안 (0) | 2023.04.11 |
| [Kubernetes Service] 3. 클러스터 외부에 서비스 연결 (0) | 2023.04.10 |
| [Kubernetes Service] 2. 서비스를 검색하는 방식 4가지 (0) | 2023.04.10 |
| [Kubernetes Service] 1. 쿠버네티스에서 서비스 (0) | 2023.04.10 |