
목차
- Python 가상환경
- 가상 환경을 따로 생성하는 이유
- venv를 통해 가상환경 생성하기
- 가상 환경에 진입하기
- mac OS에서 가상환경 진입하기
- 플라스크 모듈 다운로드하기
Python 가상환경
Python 가상 환경은 자체 라이브러리 및 종속성 세트와 함께 특정 Python 설치가 포함된 독립된 디렉토리입니다. 이를 통해 서로 간섭하지 않고 각각 고유한 버전의 Python과 설치된 패키지가 있는 서로 다른 프로젝트에 대해 격리된 환경을 만들 수 있습니다.
- Python 가상 환경의 주요 특징
- 격리
가상 환경은 특정 프로젝트에 특정한 패키지 및 종속성을 설치할 수 있는 샌드박스 환경을 제공합니다. 이러한 격리를 통해 한 가상 환경에 설치된 패키지가 다른 가상 환경의 패키지와 충돌하지 않도록 하여 종속성을 보다 효과적으로 관리할 수 있습니다. - 패키지 관리
가상 환경을 사용하면 프로젝트에 필요한 패키지와 라이브러리를 쉽게 관리할 수 있습니다. 글로벌 Python 설치 또는 다른 프로젝트에 영향을 주지 않고 패키지를 설치, 업그레이드 및 제거할 수 있습니다. 따라서 프로젝트별 종속성을 더 쉽게 유지 관리할 수 있습니다. - 버전 관리
가상 환경을 사용하면 특정 프로젝트에 사용할 Python 버전을 지정할 수 있습니다. 이 기능은 특정 Python 버전이 필요한 프로젝트에서 작업할 때 유용하며, 여러 개발 환경 간에 호환성과 일관성을 보장합니다. - 이식성
Python 가상 환경은 이식성이 뛰어나 한 머신에서 환경을 생성한 후 다른 머신에 쉽게 복제할 수 있습니다. 이는 다른 사람과 협업하거나 애플리케이션을 다른 서버 또는 호스팅 플랫폼에 배포할 때 특히 유용합니다. - 활성화 및 비활성화
가상 환경을 사용하려면 활성화해야 합니다. 활성화는 적절한 경로와 환경 변수를 설정하여 Python 인터프리터와 설치된 패키지가 해당 환경에 맞게 설정되도록 합니다. 프로젝트 작업이 끝나면 가상 환경을 비활성화하여 전역 Python 환경으로 돌아갈 수 있습니다. - 도구
Python은 가상 환경을 만들고 관리하기 위해 venv(Python 3용) 및 virtualenv(Python 2 및 3용)와 같은 기본 제공 도구를 제공합니다. 이러한 도구는 가상 환경을 설정하고 작업하는 과정을 간소화합니다.
- 격리
가상 환경 사용은 프로젝트 종속성을 유지하고 재현성을 개선하며 개발자 간의 협업을 촉진하는 데 도움이 되므로 Python 개발의 모범 사례로 간주됩니다. 또한 프로젝트가 격리되고 이식 가능하며 독립적인 상태로 유지되므로 깔끔하고 관리하기 쉬운 개발 환경을 만들 수 있습니다.
가상 환경을 따로 생성하는 이유
- 종속성 관리
프로젝트마다 종속성과 라이브러리 요구 사항이 다른 경우가 많습니다. 가상 환경을 사용하면 각 프로젝트마다 이러한 종속성을 개별적으로 관리할 수 있습니다. 이렇게 하면 다른 프로젝트나 글로벌 Python 환경과 충돌하지 않고 필요한 버전의 라이브러리 및 패키지를 설치할 수 있습니다. - 격리 및 재현성
가상 환경은 프로젝트에 제어되고 격리된 환경을 제공합니다. 프로젝트의 종속성을 가상 환경 내에 캡슐화하면 프로젝트가 독립적으로 유지되고 시스템 전체 Python 설치에 의존하지 않도록 할 수 있습니다. 이렇게 격리하면 다른 머신에서 프로젝트 환경을 더 쉽게 재현할 수 있어 호환성 문제를 최소화할 수 있습니다. - 버전 관리
가상 환경을 사용하면 특정 프로젝트의 Python 버전을 지정할 수 있습니다. 이는 특정 버전의 Python이 필요한 프로젝트를 작업할 때 특히 유용하며, 다양한 개발 환경과 배포 시나리오에서 프로젝트가 일관되게 실행되도록 보장합니다. - 협업
팀에서 작업할 때 각 팀원은 서로 다른 패키지 버전 또는 시스템 구성으로 각자의 개발 환경을 사용할 수 있습니다. 가상 환경을 사용하면 프로젝트의 가상 환경 구성을 공유하여 팀원들이 일관된 개발 환경을 가질 수 있습니다. 이를 통해 협업을 간소화하고 충돌을 줄이며 모든 사람이 동일한 종속성 집합으로 작업할 수 있습니다. - 배포 및 프로덕션 환경
가상 환경은 개발 종속성을 프로덕션 환경과 분리하는 데 도움이 됩니다. 배포 환경 전용 가상 환경을 만들어 프로덕션 환경이 충돌이나 호환성 문제 없이 애플리케이션을 실행하는 데 필요한 정확한 종속성을 갖도록 할 수 있습니다. - 간편한 설정 및 정리
가상 환경 생성은 간단한 프로세스이며 기본 제공 도구를 사용하여 빠르게 수행할 수 있습니다. 또한 프로젝트 또는 관련 가상 환경을 폐기하려는 경우 다른 프로젝트나 글로벌 Python 설치에 영향을 주지 않고 환경 디렉터리를 삭제하기만 하면 됩니다.
venv를 통해 가상환경 생성하기
1. 명령줄 인터페이스(예: 터미널 또는 명령 프롬프트)를 엽니다.
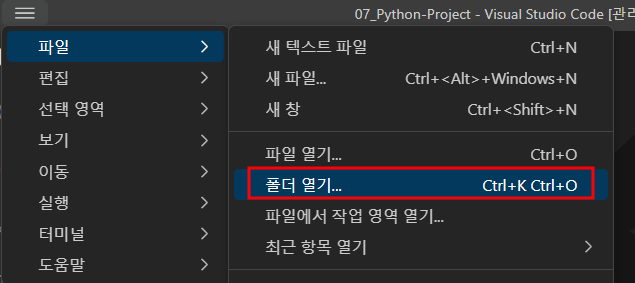
vscode를 사용한다면 터미널을 열어주면 됩니다. 저와 같은 경우 Python을 다룰 때 모두 아래 이미지에 보이는 디렉토리(폴더)에 다 넣어두기 때문에 해당 디렉토리에서 생성하겠습니다.


2. 가상 환경을 만들려는 디렉토리로 이동합니다.
명령 프롬포트에서 cd 명령어를 이용해서 이동가능하고 vscode를 사용한다면 디렉토리를 열 때 자동으로 선택됩니다.
3. 디렉토리를 생성하고 해당 디렉토리로 이동합니다.
위쪽 디렉토리 모양 버튼을 눌러 프로젝트 디렉토리안에 'venv' 디렉토리를 생성합니다. 자신이 원하는 경로에 생성하면 됩니다. 생성 후 cd 명령어를 이용해 해당 디렉토리로 이동합니다.



4. 명령어를 통해 가상환경을 생성해줍니다.
python -m venv myproject

해당 명령어를 입력하면 venvs 디렉토리 아래 myproject디렉토리가 생성되고 이 안에 다음과 같이 파일이 생성됩니다. 해당 명령어는 venv 모듈을 사용할 것인데 이름은 myprojeect로 하겠다는 뜻입니다.

이렇게 myproject라는 가상환경이 생성 되었습니다. 하지만 바로 사용은 불가능하고 가상 환경에 진입해주어야 합니다.
가상 환경에 진입하기
1. 가상환경에 진입하기 위해 가상환경 디렉토리 안에 있는 Scripts 디렉토리로 이동해줍니다.

2. 활성화 명령어를 입력해줍니다.
activate

3. 가상 환경 진입 완료 시 아래 사진처럼 앞에 가상 환경 이름이 같이 출력됩니다.

4. 가상 환경에서 빠져 나올 때는 deactivate를 입력해주면 됩니다.

플라스크 모듈 다운로드하기
플라스크를 사용하기 위해서는 플라스크 모듈을 다운로드 받아야 합니다.
1. 가상 환경 진입하기

2. 다운로드 명령어 입력하기
pip install flask

- mac OS에서 가상환경 진입하기
venvs 디렉터리(예:/Users/pahkey/venvs)에서 다음의 명령을 수행하면 가상환경으로 진입할수 있습니다.
pahkey@mymac venvs % cd myproject/bin
pahkey@mymac bin % source activate
(myproject) pahkey@mymac bin %현재 진입한 가상 환경에서 벗어나려면 deactivate라는 명령을 실행하면 됩니다.
(myproject) pahkey@mymac bin % deactivate
pahkey@mymac bin %저는 이미 다운로드 받아져 있어서 다운로드가 되지 않고 버전 확인만 진행된 것 같습니다. 다음과 같이 업그래이드하라는 경고가 출력된다면 python... --upgrade 부분을 복사해 프롬포트에 붙여넣기해 입력해줍니다.




이렇게 정말로 플라스크를 사용할 준비가 되었습니다!
'Python > Flask' 카테고리의 다른 글
| [Python Flask] ORM과 활용 (0) | 2023.05.12 |
|---|---|
| [Python Flask] 앱 팩토리와 블루 프린트 (2) | 2023.05.12 |
| [Python Flask] 플라스크(Flask) 실행하기 (3) | 2023.05.12 |
| [Python Flask] 플라스크 프로젝트 생성하기 (2) | 2023.05.12 |
| [Python Flask] 플라스크란? (0) | 2023.05.12 |