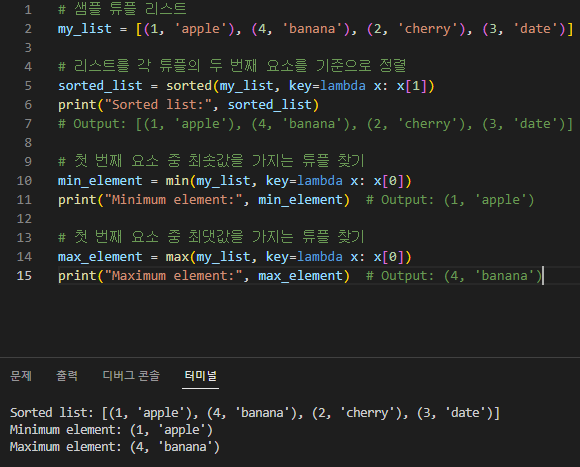
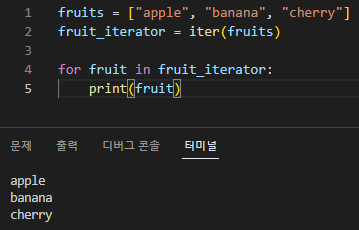
# 리스트를 각 튜플의 두 번째 요소를 기준으로 정렬 sorted_list = sorted(my_list, key=lambda x: x[1]) print("Sorted list:", sorted_list) # Output: [(1, 'apple'), (4, 'banana'), (2, 'cherry'), (3, 'date')]
# 첫 번째 요소 중 최솟값을 가지는 튜플 찾기 min_element = min(my_list, key=lambda x: x[0]) print("Minimum element:", min_element) # Output: (1, 'apple')
# 첫 번째 요소 중 최댓값을 가지는 튜플 찾기 max_element = max(my_list, key=lambda x: x[0]) print("Maximum element:", max_element) # Output: (4, 'banana')
이 예에는 my_list 튜플 목록이 있습니다. key 매개변수와 함께 sorted(), min() 및 max() 함수를 사용하여 목록을 정렬하고 다양한 기준에 따라 최소 및 최대 요소를 찾습니다. 람다 함수를 키 매개변수로 사용하여 비교 기준을 지정합니다. 이 경우 비교를 위해 각 튜플의 첫 번째 또는 두 번째 요소를 추출합니다.
이 접근 방식은 비교 값을 추출하는 적절한 키 기능을 제공하는 한 사전, 개체 또는 기타 데이터 구조 목록에도 적용할 수 있습니다.
콜백 함수
콜백 함수는 다른 함수에 인수로 전달되어 다른 함수 내의 특정 지점에서 실행되는 함수입니다. 콜백 함수를 람다로 변환하려면 명시적 함수 정의를 동일한 기능을 가진 람다 식으로 바꿔야 합니다.
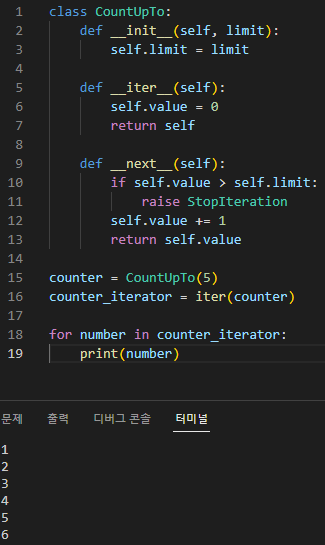
이 예제에서는 1부터 주어진 한계까지 세는 사용자 정의 iterator 클래스 CountUpTo를 정의합니다. 이 클래스는 iterator 프로토콜을 준수하기 위해 __iter__() 및 __next__() 메서드를 구현합니다. 그런 다음 클래스의 인스턴스를 만들고 iterator를 만들고 for 루프를 사용하여 숫자를 반복합니다.
Generator
Python의 Generator는 클래스가 아닌 함수를 사용하는 특별한 유형의 iterator입니다. Generator를 사용하면 보다 간결하고 메모리 효율적인 방식으로 iterator를 만들 수 있습니다. Generator 함수에는 Generator를 반복할 때 생성할 값을 지정하는 하나 이상의 yield 문이 포함되어 있습니다.
Python에서 Generator를 사용하는 방법은 다음과 같습니다.
1. yield 문을 사용하여 Generator 함수를 정의합니다.
def count_up_to(limit): value = 1 while value <= limit: yield value value += 1
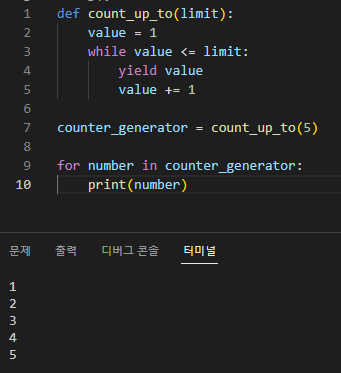
이 예에서는 1에서 주어진 한계까지 세는 Generator 함수 count_up_to를 정의합니다. 이 함수는 while 루프와 yield 문을 사용하여 숫자를 생성합니다.
2. Generator 함수를 호출하여 Generator 객체를 생성합니다.
counter_generator = count_up_to(5)
3. for 루프를 사용하여 Generator 개체를 반복합니다.
for number in counter_generator: print(number)
Generator 개체를 반복할 때 Python은 자동으로 Generator 함수를 호출하고 yield 문을 처리하므로 iterator 프로토콜을 수동으로 구현하지 않고도 값을 하나씩 생성할 수 있습니다.
Generator는 대용량 데이터 세트로 작업하거나 계산 비용이 많이 드는 일련의 값을 생성할 때 특히 유용합니다. Generator는 즉시 값을 생성하기 때문에 모든 값을 한 번에 저장하기 위해 리스트나 기타 데이터 구조를 만드는 것과 비교하여 메모리를 절약하고 성능을 향상시킬 수 있습니다.
다음은 Generator를 사용하여 피보나치 수열을 생성하는 또 다른 예입니다.
def fibonacci(limit): a, b = 0, 1 while a <= limit: yield a a, b = b, a + b
fibonacci_generator = fibonacci(10)
for number in fibonacci_generator: print(number)
이 예제에서는 주어진 한계까지 피보나치 수열을 생성하는 Generator 함수 'fibonacci'를 정의합니다. 이 함수는 'while' 루프와 'yield' 문을 사용하여 시퀀스의 숫자를 생성합니다. 그런 다음 함수에서 Generator 개체를 만들고 for 루프를 사용하여 반복합니다.
Generator 표현식
Generator 표현식과 Generator 함수는 Python에서 제너레이터를 만드는 두 가지 방법으로, 보다 메모리 효율적인 방식으로 iterator를 만드는 데 사용됩니다. 둘 다 반복하면서 즉시 값을 한 번에 하나씩 생성할 수 있습니다.
1. Generator 함수:
Generator 함수는 하나 이상의 yield 문을 포함하는 일반 Python 함수입니다. 함수가 호출되면 for 루프 또는 next() 함수를 사용하여 반복할 수 있는 제너레이터 객체를 반환합니다.
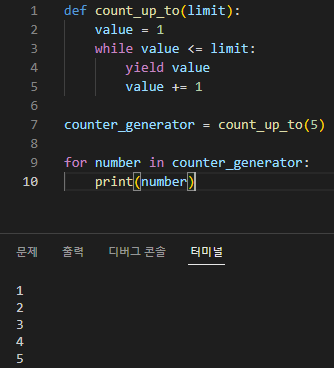
Generator 함수의 예시는 다음과 같습니다.
def count_up_to(limit): value = 1 while value <= limit: yield value value += 1
counter_generator = count_up_to(5)
for number in counter_generator: print(number)
2. Generator 표현식
제너레이터 표현식은 한 줄의 코드를 사용하여 제너레이터를 만드는 보다 간결한 방법입니다. 컴프리헨션을 나열하는 구문과 비슷하지만 대괄호 대신 괄호를 사용합니다.
Generator 표현식의 예시는 다음과 같습니다.
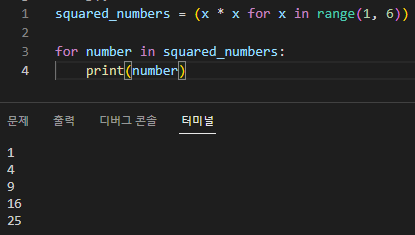
squared_numbers = (x * x for x in range(1, 6))
for number in squared_numbers: print(number)
이 예에서는 1에서 5까지 각 숫자의 제곱을 계산하는 Generator 표현식을 만듭니다. 그런 다음 'for' 루프를 사용하여 Generator 표현식을 반복할 수 있습니다.
3. 차이점 제너레이터 함수는 여러 줄의 코드를 포함하고 여러 값을 'yield'하고 루프 및 조건문과 같은 제어 구조를 사용할 수 있으므로 제너레이터 표현식보다 더 유연합니다. 제너레이터 표현식은 간단한 사용 사례에 대해 더 간결하고 읽기 쉽지만 제너레이터 함수에 비해 기능이 제한적입니다.
Generator 함수와 Generator 표현식은 모두 대규모 데이터 세트로 작업하거나 계산 비용이 많이 드는 일련의 값을 생성할 때 유용합니다. 모든 값을 한 번에 저장하기 위해 리스트 또는 기타 데이터 구조를 만드는 것과 비교하여 메모리를 절약하고 성능을 향상시킬 수 있습니다.
* close() 이 메서드는 파일 개체를 닫고 파일과 관련된 모든 시스템 리소스를 해제합니다. 파일 작업을 마치면 호출해야 합니다. 코드 블록이 실행된 후 자동으로 파일 닫기를 처리하므로 파일 작업 시 with 문을 사용하는 것이 좋습니다.
with open("file_name.txt", "r") as file_object: content = file_object.read()
이 예에서 with 문은 블록 내에서 예외가 발생하더라도 코드 블록이 실행된 후 파일이 제대로 닫히도록 합니다.
with 키워드
'with' 키워드는 코드 블록에 대한 특정 컨텍스트를 설정하고 해제하는 메서드를 정의하는 개체인 컨텍스트 관리자와 함께 사용됩니다. 'with' 문은 필요한 설정 및 정리 작업이 실행되도록 하여 파일 I/O, 소켓 또는 데이터베이스 연결과 같은 리소스 처리를 단순화합니다.
with 문이 실행되면 필요한 리소스를 설정하는 컨텍스트 관리자의 __enter__() 메서드를 호출합니다. 그러면 with 블록 내부의 코드가 이러한 리소스를 사용할 수 있습니다. 코드 블록이 완료되면 컨텍스트 관리자의 __exit__() 메서드가 호출되어 필요한 정리 작업을 수행합니다.
with 키워드의 일반적인 사용 사례는 코드 블록이 실행된 후 자동으로 파일 닫기를 처리하기 때문에 파일 작업입니다.
with open("file_name.txt", "r") as file_object: content = file_object.read()
이 예제에서 open() 함수는 컨텍스트 관리자인 파일 객체를 반환합니다. with 문은 블록 내에서 예외가 발생하더라도 코드 블록이 실행된 후 파일이 올바르게 닫히도록 합니다.
또 다른 예는 데이터베이스 연결과 함께 with 문을 사용하는 것입니다.
import sqlite3
with sqlite3.connect("example.db") as connection: cursor = connection.cursor() cursor.execute("CREATE TABLE example (id INTEGER, name TEXT)") connection.commit()
이 예에서 sqlite3.connect() 함수는 데이터베이스 연결을 처리하는 컨텍스트 관리자를 반환합니다. with 문은 코드 블록이 실행된 후 연결이 제대로 닫히도록 합니다.
with 키워드를 사용하면 리소스 관리를 간소화하고 코드 가독성을 개선하며 부적절한 리소스 정리로 인한 버그 가능성을 줄일 수 있습니다.
CSV(Comma-Separated Values)
Python CSV(쉼표로 구분된 값)는 Python 프로그래밍 언어를 사용하여 CSV 파일로 작업하는 프로세스를 나타냅니다. CSV 파일은 테이블 형식 데이터를 저장하고 교환하기 위해 널리 사용되는 데이터 형식입니다. CSV 파일의 각 줄은 레코드 또는 데이터 행을 나타내며 값은 쉼표 또는 다른 구분 기호(예: 탭, 세미콜론)로 구분됩니다. CSV 파일은 Microsoft Excel 또는 Google 스프레드시트와 같은 스프레드시트 소프트웨어로 쉽게 가져올 수 있습니다.
Python은 CSV 파일을 쉽게 읽고 쓸 수 있도록 하는 csv라는 내장 라이브러리를 제공합니다. csv 라이브러리에는 CSV 데이터를 구조화되고 효율적인 방식으로 처리하기 위한 다양한 클래스와 함수가 함께 제공됩니다. 가장 일반적으로 사용되는 csv 라이브러리 구성 요소는 다음과 같습니다.
csv.reader 이 클래스는 파일 또는 파일과 유사한 객체에서 CSV 데이터를 읽고 파일의 각 행에 대한 값 목록을 생성하는 반복 가능한 객체를 반환합니다. 행을 반복하고 필요에 따라 데이터를 처리할 수 있습니다.
csv.writer 이 클래스는 CSV 데이터를 파일 또는 파일류 객체에 기록합니다. 각각 단일 행 또는 여러 행의 데이터를 쓰는 writerow() 및 writerows()와 같은 메서드를 제공합니다.
csv.DictReader 이 클래스는 CSV 데이터를 사전으로 읽습니다. 여기서 키는 열 헤더에 해당하고 값은 각 행의 데이터입니다. 인덱스 대신 이름으로 열에 액세스하려는 경우에 유용합니다.
csv.DictWriter 이 클래스는 CSV 데이터를 사전으로 작성하여 각 행에 대한 열 헤더 및 해당 데이터를 지정할 수 있습니다.
다음은 csv 라이브러리를 사용하여 CSV 파일을 읽고 쓰는 예입니다.
import csv
# Reading a CSV file with open("input.csv", "r") as csvfile: reader = csv.reader(csvfile) for row in reader: print(row)
# Writing a CSV file data = [ ["Name", "Age", "City"], ["Alice", 30, "New York"], ["Bob", 25, "San Francisco"], ]
with open("output.csv", "w") as csvfile: writer = csv.writer(csvfile) writer.writerows(data)
이 예에서는 먼저 "input.csv"라는 CSV 파일을 읽고 각 행을 인쇄합니다. 그런 다음 "output.csv"라는 새 CSV 파일을 만들고 일부 데이터를 씁니다.
Python csv 라이브러리를 사용하면 CSV 파일로 쉽게 작업할 수 있으므로 체계적이고 효율적인 방식으로 테이블 형식 데이터를 읽고 쓰고 조작할 수 있습니다.
random 라이브러리
Python에서 CSV 데이터를 무작위로 생성하려면 내장 csv 라이브러리와 random 라이브러리를 조합하여 사용할 수 있습니다. 다음은 임의의 CSV 데이터를 생성하고 파일에 쓰는 방법의 예입니다.
# Generate random data data = [] for _ in range(num_rows): name = random.choice(names) age = random.randint(18, 60) city = random.choice(cities) data.append([name, age, city])
# Write the random data to a CSV file with open("random_data.csv", "w", newline="") as csvfile: writer = csv.writer(csvfile) writer.writerow(headers) # Write the headers writer.writerows(data) # Write the random data
이 예에서는 먼저 열 머리글과 이름 및 도시에 대한 일부 샘플 데이터를 정의합니다. 그런 다음 임의의 이름과 도시를 선택하고 임의의 연령을 생성하여 특정 수의 임의 데이터 행(num_rows)을 생성합니다. 마지막으로 임의로 생성된 데이터를 "random_data.csv"라는 CSV 파일에 기록합니다.
필요에 따라 headers, 샘플 데이터 및 num_rows를 조정하여 요구 사항에 따라 다른 임의 CSV 데이터를 생성할 수 있습니다.
생성된 데이터 출력하기
생성된 데이터를 라인별로 출력하려면 for 루프를 사용하여 data 목록의 행을 반복하고 각 행을 인쇄하면 됩니다. 다음은 데이터를 한 줄씩 인쇄하는 추가 루프가 있는 이전의 예입니다.
# Generate random data data = [] for _ in range(num_rows): name = random.choice(names) age = random.randint(18, 60) city = random.choice(cities) data.append([name, age, city])
# Write the random data to a CSV file with open("random_data.csv", "w", newline="") as csvfile: writer = csv.writer(csvfile) writer.writerow(headers) # Write the headers writer.writerows(data) # Write the random data
# Print the generated data line by line print("Generated Data:") print(', '.join(headers)) # Print the headers for row in data: print(', '.join(str(value) for value in row)) # Print the row values as a comma-separated string
이 예에서는 임의의 데이터를 CSV 파일에 쓴 후 for 루프를 사용하여 data 목록의 행을 반복합니다. 루프 내에서 join 함수를 사용하여 각 행의 값을 쉼표로 연결하고 각 값을 먼저 문자열로 변환한 다음 결과 문자열을 인쇄합니다. 이렇게 하면 헤더를 포함하여 생성된 데이터가 한 줄씩 출력됩니다.
Lambda 함수는 lambda 키워드를 사용하여 정의할 수 있는 Python의 작은 익명 함수입니다. 여러 인수를 사용할 수 있지만 단일 표현식만 가질 수 있습니다. Lambda 함수는 일반적으로 def 키워드를 사용하여 전체 함수를 정의하는 것이 불필요하거나 번거로운 짧고 간단한 작업에 사용됩니다.
람다 함수를 만드는 구문은 다음과 같습니다.
lambda arguments: expression
다음은 람다 함수의 몇 가지 예입니다.
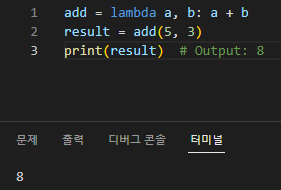
1. 두 개의 숫자를 더하는 람다 함수
add = lambda a, b: a + b result = add(5, 3) print(result) # Output: 8
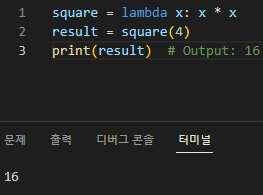
2. 숫자를 제곱하는 람다 함수
square = lambda x: x * x result = square(4) print(result) # Output: 16
람다 함수는 종종 함수를 인수로 받아들이는 map(), filter() 및 sorted()와 같은 내장 함수와 함께 사용됩니다. 예를 들어 람다 함수를 사용하여 숫자 목록을 내림차순으로 정렬합니다.
람다 함수는 범위와 기능이 제한되어 있습니다. 더 복잡한 작업이 필요하거나 여러 표현식이 필요한 경우 def 키워드로 정의된 정규 함수를 사용하는 것이 좋습니다.
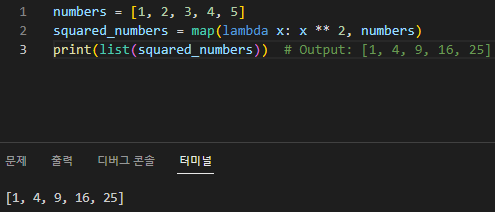
인라인 람다
인라인 람다는 단순히 식 내에서 직접 사용되거나 변수에 할당하지 않고 다른 함수에 대한 인수로 사용되는 람다 함수입니다. Lambda 함수는 익명 함수이므로 이름이 없으며 lambda 키워드를 사용하여 정의됩니다. 인라인 람다는 짧은 기간 동안 작고 간단한 함수가 필요하고 def 키워드를 사용하여 전체 함수를 정의하고 싶지 않을 때 유용할 수 있습니다.
이 예에서 sorted() 함수는 정렬 순서를 결정하는 함수인 key 인수를 사용합니다. 인라인 람다 함수 lambda x: -x는 각 숫자를 부정하여 sorted() 함수가 목록을 내림차순으로 정렬하도록 합니다. 마찬가지로 map(), filter() 또는 함수를 인수로 허용하는 다른 함수와 함께 인라인 람다를 사용할 수 있습니다.
람다와 인라인 람다 차이점
람다 함수는 익명 함수로, 간단한 함수를 정의하는 데 사용되며 일회성으로 사용됩니다. 인라인 람다는 코드의 특정 위치에서 즉시 사용할 수 있는 람다 함수를 설명하는 데 사용되는 용어입니다.
둘 다 간단한 함수를 정의할 때 사용되지만, 인라인 람다는 일반적으로 다른 함수의 인수로 전달되거나 직접 계산에 사용됩니다. 람다 함수는 다음과 같이 정의할 수 있습니다:
# 결과를 리스트로 변환하고 출력 result = list(doubled_numbers) print(result) # Output: [2, 4, 6, 8, 10]
여기서 map 함수에 전달된 람다 함수는 인라인으로 사용되었습니다. 따라서 람다 함수와 인라인 람다 함수는 동일한 개념을 설명하지만, 인라인 람다는 특정 위치에서 즉시 사용되는 람다 함수를 설명할 때 사용되는 용어입니다. 이 때 출력을 하고 싶다면 리스트로 변환하고 print로 출력이 가능합니다.
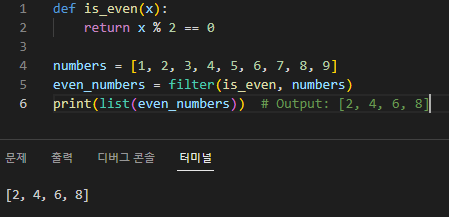
Filter 함수
'filter()' 함수는 특정 조건에 따라 iterable(목록, 튜플 또는 세트와 같은)에서 요소를 필터링하는 데 사용되는 내장 Python 함수입니다. 이 함수는 부울 값을 반환하는 함수와 필터링할 iterable의 두 가지 인수를 사용합니다. filter() 함수는 주어진 함수를 iterable의 각 요소에 적용하고 함수가 True를 반환하는 요소만 포함하는 새로운 iterable을 반환합니다.
다음은 filter() 함수의 구문입니다.
filter(function, iterable)
function은 단일 인수를 취하고 부울 값(True 또는 False)을 반환하는 함수여야 합니다. 함수 대신 None이 제공되면 filter() 함수는 부울 컨텍스트에서 False로 평가되는 모든 요소를 제거합니다(예: None, False, 0, 빈 컬렉션, 등.).
filter() 함수는 적절한 생성자(예: list(), tuple())를 사용하여 리스트, 튜플 또는 기타 컬렉션 유형으로 변환될 수 있는 반복 가능한 필터 객체를 반환한다는 점을 명심하세요.
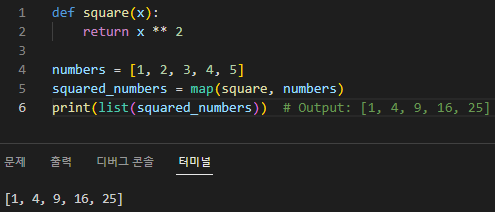
Map 함수
map() 함수는 지정된 함수를 iterable의 각 요소(예: 목록, 튜플 또는 집합)에 적용하고 결과를 포함하는 새 iterable을 만드는 데 사용되는 내장 Python 함수입니다. map() 함수는 요소에 적용하려는 함수와 처리할 iterable의 두 가지 인수를 사용합니다.
다음은 map() 함수의 구문입니다.
map(function, iterable)
function은 단일 인수를 취하고 값을 반환하는 함수여야 합니다. map() 함수는 이 함수를 iterable의 각 요소에 적용하고 결과를 포함하는 새로운 iterable을 생성합니다.
튜플(tuple)은 목록과 유사하지만 몇 가지 중요한 차이점이 있는 내장 Python 데이터 구조입니다. 튜플은 둥근 괄호(소괄호)로 묶인 정렬되고 변경할 수 없는 요소 모음입니다. 튜플의 요소는 다른 튜플, 목록 또는 사전을 포함하여 다양한 데이터 유형일 수 있습니다.
다음은 튜플의 몇 가지 주요 기능입니다.
정렬됨 튜플은 요소의 순서를 유지하므로 목록처럼 인덱스를 사용하여 요소에 액세스할 수 있습니다.
불변성 리스트와 달리 튜플은 생성 후 수정할 수 없습니다. 즉, 튜플에서 요소를 추가, 제거 또는 변경할 수 없습니다. 이 불변성은 시간이 지남에 따라 변경되지 않아야 하는 요소 모음을 만들려는 경우에 유용할 수 있습니다.
목록보다 빠름 튜플은 변경할 수 없기 때문에 특히 대용량 데이터 세트의 경우 목록보다 메모리 효율적이고 처리 속도가 빠릅니다.
사전에서 키로 사용할 수 있습니다. 튜플은 해시 가능하고 변경할 수 없기 때문에 목록과 달리 사전에서 키로 사용할 수 있습니다.
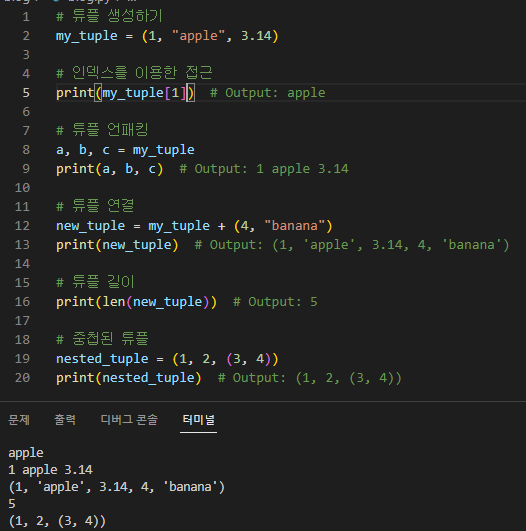
다음은 튜플을 만들고 사용하는 방법의 예입니다.
# 튜플 생성하기 my_tuple = (1, "apple", 3.14)
# 인덱스를 이용한 접근 print(my_tuple[1]) # Output: apple
# 튜플 언패킹 a, b, c = my_tuple print(a, b, c) # Output: 1 apple 3.14
튜플은 변경할 수 없기 때문에 목록에서와 같이 '추가', '확장' 또는 '제거'와 같은 작업을 수행할 수 없습니다. 튜플을 수정하려면 일반적으로 원하는 변경 내용으로 새 튜플을 만들어야 합니다.
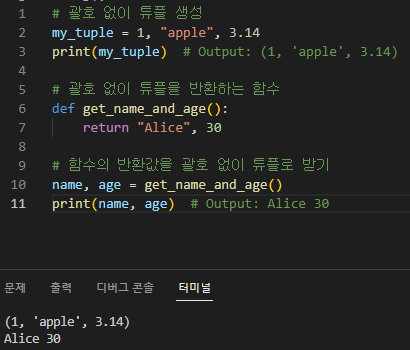
괄호 없이 튜플 사용하기
Python에서 괄호 없이 튜플을 사용할 수 있습니다. 이를 암시적(implicit) 튜플이라고 합니다. 튜플을 만들 때 괄호를 생략하면, Python은 자동으로 요소들을 튜플로 인식합니다. 이런 방식으로 튜플을 생성하는 것을 "tuple packing"이라고도 합니다.
예시:
# 괄호 없이 튜플 생성 my_tuple = 1, "apple", 3.14 print(my_tuple) # Output: (1, 'apple', 3.14)
# 괄호 없이 튜플을 반환하는 함수 def get_name_and_age(): return "Alice", 30
# 함수의 반환값을 괄호 없이 튜플로 받기 name, age = get_name_and_age() print(name, age) # Output: Alice 30
괄호 없이 튜플을 사용할 때 주의해야 할 점은, 연산자 우선순위와 혼동이 없어야 한다는 것입니다. 예를 들어, 튜플을 더하기 연산과 함께 사용하려면 괄호를 사용하여 명시적으로 표현해야 합니다.
예시:
# 튜플 더하기 연산을 사용할 때는 괄호가 필요 result = (1, 2) + (3, 4) print(result) # Output: (1, 2, 3, 4)
튜플 변수 값 교환
Python에서는 튜플을 사용하여 두 변수의 값을 쉽게 교환할 수 있습니다. 이 방법은 임시 변수가 필요하지 않으며 구문이 간결합니다.
다음은 튜플을 사용하여 두 변수의 값을 교환하는 예입니다.
# 초기값이 있는 변수들 a = 5 b = 10
# 튜플을 사용하여 값 교환 a, b = b, a
# 교환된 값 출력 print("a:", a) # Output: a: 10 print("b:", b) # Output: b: 5
이 예에서는 튜플 (b, a)가 생성된 다음 해당 값이 변수 a 및 b로 압축 해제됩니다. 결과적으로 임시 변수 없이도 두 변수의 값이 교환됩니다.
튜플로 함수 값 반환
Python에서는 튜플을 사용하여 함수에서 여러 값을 반환할 수 있습니다. 이를 달성하려면 함수에서 원하는 값을 포함하는 튜플을 반환하기만 하면 됩니다. 함수를 호출할 때 반환된 튜플을 별도의 변수로 압축 해제할 수 있습니다.
다음은 튜플을 사용하여 여러 값을 반환하는 함수의 예입니다.
def get_name_and_age(): # 이름과 나이 값을 정의합니다 name = "Alice" age = 30
# 이름과 나이를 튜플 형태로 반환합니다 return name, age
# 함수를 호출하고 반환된 튜플을 언팩합니다 person_name, person_age = get_name_and_age()
# 언팩된 값을 출력합니다 print("Name:", person_name) # Output: Name: Alice print("Age:", person_age) # Output: Age: 30
이 예에서 get_name_and_age 함수는 이름과 나이를 포함하는 튜플을 반환합니다. 함수를 호출할 때 반환된 튜플은 person_name 및 person_age 변수로 풀립니다.
리스트와 딕셔너리에서 튜플 사용하기
튜플을 목록 내의 요소로 사용하고 사전의 키 또는 값으로 사용할 수 있습니다. 다음은 목록과 사전 모두에서 튜플을 사용하는 방법을 보여주는 예입니다.
1. 리스트에서 튜플 사용
# 튜플을 포함하는 리스트 생성 persons = [("Alice", 30), ("Bob", 25), ("Charlie", 22)]
# 리스트 내의 튜플 요소들에 접근하고 출력 for name, age in persons: print(f"Name: {name}, Age: {age}")
이 예에서는 이름과 나이가 포함된 튜플을 포함하는 'persons'라는 목록을 만듭니다. 그런 다음 목록을 반복하고 정보를 인쇄하기 위해 각 튜플을 name 및 age 변수로 압축을 풉니다.
# 튜플 키를 사용하여 딕션너리에서 요소에 액세스하고 출력 for (subject, name), grade in grades.items(): print(f"Subject: {subject}, Name: {name}, Grade: {grade}")
이 예에서는 튜플을 키로 사용하여 grades라는 딕셔너리을 만듭니다. 키는 과목과 학생 이름으로 구성되며 값은 해당 과목에 대한 학생의 성적을 나타냅니다. 그런 다음 items() 메서드를 사용하여 사전을 반복하고 각 키-값 쌍을 변수 subject, name 및 grade로 풀어 정보를 인쇄합니다.
객체별 특징
가변 객체(mutable)
생성 후 변경 가능: 초기화 후 상태나 내용을 수정할 수 있습니다.
Python의 예: 목록, 사전 및 집합은 변경 가능한 개체의 예입니다.
내부 수정: 변경 가능한 개체에 대한 작업은 새 개체를 만들지 않고 상태를 직접 변경할 수 있습니다.
잠재적으로 메모리 효율성이 낮음: 변경 가능한 객체는 변경될 수 있으므로 크기가 커지거나 줄어들 때 더 많은 메모리를 사용할 수 있습니다.
사전 키로 사용하기에 적합하지 않음: 변경 가능한 객체는 상태가 변경되어 해싱 프로세스에 영향을 줄 수 있기 때문에 사전에서 키로 사용할 수 없습니다.
불변 객체(immutable)
생성 후 변경할 수 없음: 초기화 후에도 상태 또는 내용이 일정하게 유지됩니다.
Python의 예: 문자열, 튜플, 정수 및 부동 소수점은 불변 객체의 예입니다.
수정을 위한 새 객체: 불변 객체를 변경하는 것처럼 보이는 작업을 수행할 때 대신 새 객체가 생성됩니다.
메모리 효율성 향상: 변경 불가능한 개체는 크기와 내용이 수명 기간 동안 일정하게 유지되므로 메모리를 덜 사용합니다.
사전 키로 사용하기에 적합: 불변 객체는 상태가 일정하게 유지되어 일관된 해싱 프로세스를 보장하기 때문에 사전의 키로 사용할 수 있습니다.
재귀 함수의 맥락에서 메모("memorandum"의 줄임말)는 비용이 많이 드는 함수 호출의 결과를 캐싱하고 재사용하여 재귀 알고리즘을 최적화하는 데 사용되는 메모이제이션이라는 기술을 말합니다. 이는 특히 함수에 겹치는 하위 문제가 있는 경우 재귀 함수의 성능을 크게 향상시킬 수 있습니다.
재귀 함수가 동일한 입력으로 여러 번 호출되면 동일한 결과를 반복적으로 계산하여 불필요한 오버헤드가 발생합니다. 메모이제이션은 이전 계산 결과를 사전이나 배열과 같은 데이터 구조에 저장하고 필요할 때 찾아봄으로써 이를 방지하는 데 도움이 됩니다.
재귀 함수에서 메모화를 구현하는 방법은 다음과 같습니다.
이전에 계산된 하위 문제의 결과를 저장할 메모 테이블(일반적으로 딕셔너리 또는 리스트)을 만듭니다.
특정 입력으로 재귀 함수가 호출되면 해당 입력에 대한 결과가 이미 메모 테이블에 있는지 확인하십시오.
결과가 있으면 다시 계산하지 않고 메모 테이블에서 직접 반환합니다.
결과가 없으면 평소대로 계산하고 결과를 메모 테이블에 저장한 후 반환합니다.
다음은 재귀 피보나치 함수에서 메모이제이션을 사용하는 예입니다.
def fibonacci_memo(n, memo=None): if memo is None: memo = {} # 메모 테이블 초기화
if n in memo: return memo[n] # 캐시 result 반환
if n == 0: result = 0 elif n == 1: result = 1 else: result = fibonacci_memo(n - 1, memo) + fibonacci_memo(n - 2, memo)
memo[n] = result # Store the result in the memo table return result
n = 10 result = fibonacci_memo(n) print(f"Fibonacci({n}) = {result}") # Output: Fibonacci(10) = 55
이 예에서 fibonacci_memo 함수는 memo라는 사전을 사용하여 이전에 계산된 피보나치 수의 결과를 저장합니다. 이는 메모이제이션이 없는 순진한 재귀 구현과 비교하여 특히 n의 더 큰 값에 대해 함수의 성능을 크게 향상시킵니다.
Early Return
빠른 리턴(early retrun)은 함수가 끝에 도달하기 전에 함수에서 값을 반환하는 것을 나타냅니다. 이는 일반적으로 코드를 단순화하고 중첩된 조건문의 필요성을 줄이기 위해 수행됩니다. Early Return은 특정 조건이 충족될 때 함수가 일찍 종료되도록 하여 코드를 더 읽기 쉽고 이해하기 쉽게 만들 수 있습니다. Python에서 빠른 리턴을 사용하려면 함수 내의 어느 지점에서나 return 문을 사용할 수 있습니다.
다음은 Python 함수에서 조기 반환을 사용하는 방법을 보여주는 몇 가지 예입니다.
1. 숫자가 짝수인지 확인
1) 빠른 리턴을 사용하지 않은 경우
def is_even(number): if number % 2 == 0: return True else: return False
def find_smallest_positive(numbers): smallest = None for number in numbers: if number > 0: if smallest is None or number < smallest: smallest = number return smallest
def find_smallest_positive(numbers): smallest = None for number in numbers: if number > 0: if smallest is None or number < smallest: smallest = number if smallest == 1: # 가장 작은 양수가 1이라면 일찍 리턴(반환)합니다. return smallest return smallest
두 예제 모두 조기 반환을 사용하면 코드가 단순화되고 읽기가 더 쉬워집니다. 첫 번째 예에서는 'else' 문을 제거하고 짝수가 아닌 경우 함수에서 직접 'False'를 반환합니다. 두 번째 예에서 함수는 리스트의 나머지 부분을 확인할 필요 없이 값 1을 찾는 즉시 가장 작은 양수를 반환합니다.
리스트 평면화
리스트 평면화는 중첩 리스트(다른 리스트을 포함하는 리스트)을 단일 수준 리스트으로 변환하는 프로세스를 의미하며, 여기서 중첩 리스트의 모든 요소는 중첩 구조 없이 단일 리스트으로 병합됩니다. 즉, 리스트 평면화는 리스트들을 가져와서 한 수준으로 "평면화"하므로 결과 리스트에서 모든 요소에 직접 액세스할 수 있습니다.
중첩된 리스트가 다음과 같이 주어지는 경우를 예로 들겠습니다.
nested_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
리스트을 평면화하면 다음과 같은 결과가 발생합니다.
flattened_list = [1, 2, 3, 4, 5, 6, 7, 8, 9]
Python에서 리스트을 평면화하는 방법에는 여러 가지가 있습니다. 다음은 리스트 평면화를 사용하는 예시입니다.
nested_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] flattened_list = [item for sublist in nested_list for item in sublist]
이 예에서 중첩 리스트 [[1, 2, 3], [4, 5, 6], [7, 8, 9]]는 단일 리스트 [1, 2, 3, 4, 5, 6, 7, 8, 9]. 리스트 내포는 중첩된 리스트의 각 하위 리스트을 반복한 다음 하위 리스트의 각 항목을 반복하여 평면화된 리스트에 각 항목을 추가합니다.
다른 방법으로는 재귀 함수를 사용하여 입력 리스트을 재귀적으로 처리하고 해당 요소를 출력 리스트에 추가하는 방법이 있습니다. 요소가 리스트이면 함수는 해당 하위 리스트에서 재귀적으로 호출됩니다. 예를 들면 다음과 같습니다.
def flatten_list(input_list, output_list=None): if output_list is None: output_list = []
for item in input_list: if isinstance(item, list): flatten_list(item, output_list) # 하위 목록에 대한 재귀 호출 else: output_list.append(item) # 출력 리스트에 항목 추가
이 예에서 flatten_list 함수는 입력 리스트(중첩 가능)과 선택적 출력 리스트을 사용합니다. 입력 리스트을 반복하고 요소가 리스트인 경우 해당 하위 리스트에 대해 재귀 호출을 수행합니다. 요소가 리스트이 아닌 경우 항목을 출력 리스트에 추가합니다. 출력 리스트은 입력 리스트의 모든 요소를 처리한 후 반환됩니다.