우리가 통신을 진행하기 위해서 IP 주소를 먼저 따라가게 됩니다. 하지만 부여된 IP를 숫자로만 암기하기에는 무리가 있습니다. 접속하고자 하는 사이트에 대한 연관성은 없다시피 하고, IP는 쉽게 변경될 수 있기 때문입니다. 수시로 바뀌는 IP를 매번 외우고 있을 수는 없기 때문에 등장한 체계가 있습니다.
DNS(Domain Name System)
이름에서 유츄할 수 있듯 IP에 도메인 이름을 부여해 도메인을 입력하면 해당하는 IP로 이동하게 해주는 기능입니다. 우리가 구글에 접근하기 위해서는 "https://google.com/"이나 "142.250.196.100"를 입력해 접속하게 됩니다. 단순하게 보더라도 무작위 숫자를 암기하기 보다 구글을 뜻하는 도메인을 활용하는 것이 더 수월할 것입니다. 따라서 특별한 경우가 아니라면 대부분 도메인 주소를 사용해 IP 주소로 변환하는 DNS 서버를 사용하고 있는 것입니다.
DNS의 체계와 작동원리까지 다루기에 신입 개발자나 엔지니어에게 이정도까지 바라지는 않을 것 같아 나중에 네트워크 파트를 심도 있게 공부할 때 다뤄보도록 하겠습니다.
이전 포스팅에서 IP 체계를 다룰 때 단점 중 하나는 "하나의 IP를 가지고 있는 서버에서 두 개 이상의 애플리케이션을 다루고 있다면 이를 구분할 수 없다."라고 했습니다. 이를 해결하기 위한 방법이 바로 포트를 이용해 애플리케이션을 구분하는 방법입니다.
이와 같이 TCP 세그먼트에는 출발지 포트와 목적지 포트의 정보가 있어 하나의 IP만을 사용하더라도 애플리케이션을 구분할 수 있습니다. 예를 들면 다음과 같습니다.
서비스 플랫폼 IP로 접근한 후 영상을 이용하기 위해 클릭하면 11000번 포트에서 출발해 10000번 포트로 도착합니다. 이를 통해 영상 시청이 가능합니다. 이러한 원리로 여러 애플리케이션을 한 곳에서 운영할 수 있게 됩니다.
포트 번호
포트 번호는 0~65535까지 값을 가지고 있으며, 구성은 크게 다음과 같습니다.
0~1023: Well-known port
1024~40151: Registered port
40152~65535: Dynamic port
Well-known port는 직역하면 잘 알려진 포트를 뜻합니다. 일반적으로 잘 알려진 80번(HTTP), 443번(HTTPS)와 같은 포트를 뜻합니다. Registered port는 Well-known port처럼 많이 사용되지는 않지만 특정 소프트웨어나 애플리케이션이 필요로 할 때 사용되는 포트입니다. 나머지는 일반적으로 자주 사용되지 않기 때문에 임시로 사용하는 용도로 쓰이기도 합니다.
이렇게 구분하는 포트가 겹치게 되면 어느 서비스 포트로 데이터를 보내야할지 명확하지 않아 데이터 손실이 발생하기 때문입니다. IP도 마찬가지로 동일한 IP값이 할당되면 주소 충돌이 발생해 패킷이 올바르게 라우팅 되지 않습니다. 때문에 잘 알려진 포트인 0~1023번까지는 사용하지 않는 것이 좋습니다.
그렇다면 잘알려진 포트 중 우리가 알아둬야 할 중요한 포트들은 무엇이 있을까요?
굳이 다 암기할 필요는 없지만 알아두면 좋을 포트들을 정리했습니다. 앞으로 개발이나 클라우드 업계에서 공부하다 보면 자주 접하실 겁니다.
포트 번호
TCP
UDP
설명
7
O
O
ECHO 프로토콜
20
O
파일 전송 프로토콜 (FTP, File Transfer Protocol) - 데이터 포트
21
O
파일 전송 프로토콜 (FTP, File Transfer Protocol) - 제어 포트
22
O
시큐어 셀 (SSH, Secure SHell) - ssh, scp, sftp같은 프로토콜 및 포트 포워딩
23
O
텔넷 프로토콜(Telnet Protocol) - 암호화되지 않은 텍스트 통신
25
O
SMTP (Simple Mail Transfer Protocol) - 이메일 전송에 사용
53
O
O
도메인 네임 시스템 (DNS, Domain Name System)
67
O
BOOTP(부트스트랩 프로토콜) 서버, DHCP로도 사용
68
O
BOOTP(부트스트랩 프로토콜) 클라이언트, DHCP로도 사용
80
O
O
HTTP (HyperText Transfer Protocol) - 웹페이지 전송
110
O
POP3(Post Office Protocol version 3) - 전자우편 가져오기에 사용
143
O
인터넷 메시지 접속 프로토콜 4 (IMAP4, Internet Message Access Protocol 4) - 이메일 가져오기에 사용
이전 포스팅에서 OSI 7 계층의 구성 요소와 특징에 대해 살펴봤습니다. 그렇다면 이번에는 이 구조를 통해 어떻게 통신이 이루어지는지 간단하게 살펴보겠습니다.
인터넷 통신 방법
클라이언트가 서버에 A라는 명령을 요청한다고 가정해 봅시다. 그렇다면 다음 그림과 같은 형태를 띨 것입니다.
이렇게 서버와 클라이언트를 이어주는 인터넷 망이 이와 같이 단순하다면 편하겠지만 안타깝게도 저희가 사는 세상은 훨씬 복잡한 인터넷 망 체계를 가지고 있습니다.
그렇다면 이와 같은 상태에서는 어떻게 데이터를 주고 받을 수 있을까요?
1. IP(Internet Protocol)
첫 번째는 전송하고자 하는 데이터에 IP 패킷을 추가해 전달하는 방법입니다. 출발지 IP와 목적지 IP 등 정보를 데이터에 붙여 전달하는 방식입니다.
데이터에 IP 패킷을 부착해 전송합니다.출발지와 목적지 IP를 지정해 명령을 주고 받습니다.
이와 같은 방법으로 데이터를 주고 받을 수 있게 됐지만 다음과 같은 한계가 있습니다.
비연결성 직접적으로 연결이 돼있지 않다보니 상대가 패킷을 받을 수 있는 상황인지 구분할 수 없습니다. 때문에 패킷을 받을 대상이 없거나, 서비스 불능 상태라고 하더라도 패킷을 전송하게 됩니다.
비신뢰성 중간에 패킷이 소실되거나, 보낸 패킷의 순서가 바뀌어 전송될 경우 처리에 문제가 발생할 수 있습니다. 또한 한 서버에 애플리케이션이 2개가 동작하고 있다고 가정했을 때, 이를 구분할 방법이 없습니다.
2. TCP(Transmission Control Portocol)
IP의 한계를 극복하기 위해 트렌스포트(전송) 계층의 TCP를 사용하게 됐습니다. 우선 TCP/IP의 계층 구조는 다음과 같습니다.
TCP/IP와 OSI 모델을 비교한 것. 프로토콜은 더 다양하게 존재하지만 나중에 알아보겠다.
TCP/IP 모델은 다음과 같이 데이터를 전송하게 됩니다.
TCP의 특징은 다음과 같습니다.
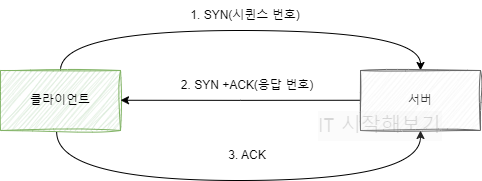
2-1. TCP 3-way handshake
TCP는 데이터 전송을 시작하기 전 다음 과정을 통해 두 시스템이 연결이 잘 됐는지 확인하는 작업을 진행합니다.
조금 쉽게 설명하자면 다음과 같이 설명할 수 있을 것 같습니다.
SYN 전송: 아 혹시 지금 연결 가능할까요?(SYN) - 클라이언트가 서버에 연결을 요청하는 패킷을 보냅니다.
SYN + ACK 전송: 네 요청(SYN) 잘 받았구요. 지금 연결 가능합니다(ACK). - 서버가 요청을 잘 받았고, 연결 요청을 수락한다는 신호를 함께 보냅니다.
ACK 전송: 연결됐습니다. 감사합니다.(ACK) - 클라이언트가 서버의 응답을 받고, 연결이 잘 이루어졌다고 알려줍니다.
이 과정을 통해 연결 상태를 확인하고, 데이터를 주고받으며 전달이 잘 되었는지 확인하게 됩니다. 이를 통해 전달받은 데이터가 신뢰성을 갖게 됩니다.
2-2 TCP 순서 보장
데이터가 전달되는 과정에서 여러 패킷으로 쪼개 전달하게 됩니다. 이 때 패킷에 순서가 부여됨으로 전송 중 순서가 뒤바뀌더라도 걱정할 필요가 없습니다.
3. UDP(User Datagram Protocol)
UDP는 TCP는 달리 신뢰성을 보장할만한 기능들이 전혀 없습니다. 데이터 전송은 신뢰성이 바탕이 돼야 하는 것이 핵심입니다. 때문에 UDP는 제한적인 용도로 사용됩니다.
음성 데이터나 실시간 스트리밍과 같이 시간에 민감한 프로토콜이나 애플리케이션을 사용하는 경우, 사내 방송아니 증권 시세 데이터 전송에 사용되는 멀티캐스트처럼 단방향으로 다수의 단말과 통신해 응답을 받기 어려운 환경에서 주로 사용됩니다.
이와 같은 경우 데이터 신뢰도 보다는 신속성에 민감한 경우입니다. 실시간 스트리밍을 예시로 들면 영상은 초당 30~120회의 정지된 사진이 빠르게 바뀌며 움직이는 듯한 영상처럼 보이는 원리를 이용합니다. 이때에는 패킷이 1~2개 소실된다고 하더라도 우리가 시청하는 데는 큰 영향이 없습니다.
하지만 이 수많은 패킷을 하나하나 확인하고 다듬게 되면 버퍼링이 걸리거나 멈칫 거리는 증상이 생길 것입니다. 사람들이 서비스를 평가할 때는 패킷이 1~2개 소실되는 것보다 버퍼링 걸리는 것을 더 안좋은 시선으로 보기 때문에 UDP를 사용하고 있습니다.
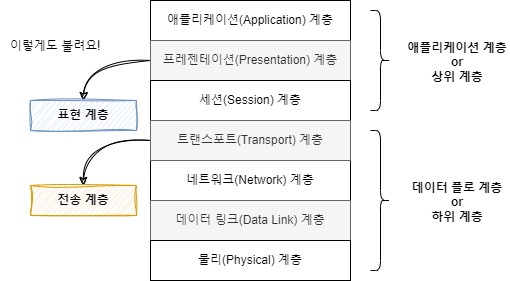
OSI 7 계층은 데이터가 네트워크를 통해 이동하는 과정을 7단계로 나누어 쉽게 설명하는 모델입니다. OSI 7 계층 모델은 다음과 같이 구성 돼 있습니다.
복잡하게만 보이는 데이터 전송 과정을 이 모델로 나누어 보면 이해하기 수월해집니다. 그리고 이 모델은 다음과 같이 나뉘기도 합니다.
이런 계층 분류는 계층의 역할과 목표에 따른 것입니다. 데이터 플로 계층은 데이터를 상대에게 잘 전달하는 역할을 가지고 있습니다. 그리고 상위 계층은 사용자나 응용 프로그램과 상호작용하여 데이터를 보내고 받는 역할을 하게 됩니다.
각 계층별 특징
1. 물리(Physical) 계층
물리 계층은 OSI 7계층의 첫 번째 계층으로 물리적 연결과 관련된 정보를 전달합니다. 주로 전기적, 물리적인 특징을 다루며 Bits를 주고 받습니다. 물리 계층 장비는 들어온 전기 신호를 그대로 잘 전달하는 것을 목적으로 하므로 전기 신호가 장비에 들어오면 이 전기 신호를 재생성해 내보냅니다. 이 장비는 주소의 개념이 없어 전기 신호가 들어온 포트를 제외하고 모든 포트에 같은 전기 신호를 전송합니다.
주요 장비: 허브(Hub), 리피터(Repeater), 케이블(Cable), 커넥터(Connector) 등
2. 데이터 링크(Data Link) 계층
데이터 링크는 두 번째 계층 즈로 전기 신호를 모아 정보를 처리합니다. 물리 계층과는 달리 전기 신호를 정확히 전달하기 보다는 주소 정보를 정의하고 통신이 원활히 하는 데 초점이 맞춰져 있습니다. 때문에 출발지와 도착지 주소를 확인하고 자신에게 보낸 것이 맞는지, 또는 자신이 처리해야 하는지에 대해 검사한 후 데이터 처리를 수행합니다.
이 계층에서는 전기 신호를 모아 데이터 형태로 처리하므로 데이터에 대한 에러를 탐지하거나 고치는 역할을 수행합니다. 신뢰할 수 있는 현대 물리 계층과 달리 과거에는 신뢰할 수 없는 미디어를 이용해 통신하는 경우도 많았기에 데이터 링크 계층에서 통해 에러를 탐지하고 고치거나 재전송했다고 합니다. 현대 이더넷 기반 네트워크 2계층에서는 에러를 탐지하는 역할만 수행하고 있습니다.
주소 체계의 등장은 일대 일 통신에서 일대 다수 통신이 가능해졌다는 뜻이 됩니다. 이 때문에 무작정 데이터를 전송하지 않고, 받는 사람이 현재 데이터를 받을 수 있는지 확인하는 작업부터 진행합니다. 이를 플로 컨트롤(Flow Control)이라고 부릅니다. 이에 대한 방식은 다음에 자세히 다뤄보겠습니다.
이 계층에서는 MAC 주소라는 체계를 사용합니다.
주요 장비: 네트워크 인터페이스 카드(Network Interface Card), 스위치(Switch)
3. 네트워크(Network) 계층
네트워크 계층에서는 데이터 링크 계층에서 물리적 MAC 주소 체계를 사용하는 것처럼 논리적 IP 주소 체계를 사용합니다. MAC 주소가 보통은 고정돼 있는 것에 반해 IP 주소는 사용자가 환경에 맞게 변경해 사용할 수 있습니다. IP 주소의 체계는 여기에 정리해 두었습니다.
이 계층 장비는 네트워크 주소 정보를 이용해 자신이 속한 네트워크와 원격지 네트워크를 구분할 수 있고 원격지 네트워크로 가려면 어디로 가야 하는지 경로를 지정할 수 있습니다. 네트워크 계층에서 사용하는 장비인 라우터는 IP 주소를 사용해 최적의 경로를 찾아 해당 경로로 패킷을 전송하는 역할을 합니다.
주요 장비: 라우터(Router)
4. 트랜스포트(Transport) 계층
물리 계층에서 네트워크 계층까지 담당하는 역할이 신호와 데이터를 올바른 위치로 보내고 실제 신호를 만들어 보낸다면, 트랜스포트(전송) 계층은 해당 데이터들이 실제로 정상적으로 잘 보냈졌는가를 확인하는 역할을 합니다. 데이터를 패킷으로 나누어 전송하는 패킷 네트워크는 전송 중 패킷이 유실되거나 순서가 바뀌는 경우가 생기기도 합니다. 이 문제를 해결하기 위해 패킷이 유실되거나 순서가 바뀌었을 때 바로 잡아주는 역할을 이 계층이 담당합니다.
패킷을 분할할 때 패킷 헤더에는 보내는 순서와 받는 순서를 적어 통신합니다. 따라서 패킷이 유실됐다면 재전송을 요청하고 순서가 바뀌더라도 바로 잡을 수 있습니다. 패킷에 보내는 순서를 명시한 것이 시퀸스 번호(Sequence Number)이고 받는 순서를 나타낸 것이 ACK 번호(Acknowledgement Number)입니다. 이 뿐만 아니라 장치 내의 많은 어플리케이션을 구분할 수 있도록 포트 번호(Port Number)를 사용해 상위 애플리케이션을 구분합니다.
트랜스포트 계층의 로드 밸런서는 시퀸스와 ACK 번호를 이용해 부하를 분산하고, 방화벽은 보안 정책을 수립해 패킷을 통과, 차단하는 기능을 수행합니다.
주요 장비: 로드 밸런서, 방화벽
5. 세션(Session) 계층
양 끝단의 응용 프로세스가 연결을 성립하도록 도와주고 연결이 안정적으로 유지되도록 관리하고 작업 완료 후에는 이 연결을 끊는 역할을 합니다. 흔히 부르는 '세션'을 관리한다고 하는데, TCP/IP 세션을 만들고 없애며, 에러로 중단된 통신에 대한 에러 복구와 재전송을 수행합니다. 이를 위해 API(Application Programming Interface)를 사용합니다.
6. 프레젠테이션(Presentation) 계층
표현 방식이 다른 애플리케이션이나 시스템 간의 통신을 돕기 위해 데이터 형식을 JEPG나 PDF처럼 정의하고, 애플리케이션 계층에서 받은 데이터를 적절한 형식으로 변환하거나 압축하는 역할을 수행합니다. 데이터의 압축, 암호화, 인코딩, 형식 변환 등의 과정을 처리해 서로 다른 시스템 간에 호환성 있는 데이터를 교환 가능하게 만들어줍니다.
7. 애플리케이션(Application) 계층
애플리케이션 프로세스를 정의하고 애플리케이션 서비스를 수행합니다. 여기에는 네트워크 소프트웨어의 UI(User Interface)처럼 사용자가 직접 상호작용하는 소프트웨어나 서비스뿐만 아니라 이메일, 파일 전송, 웹 브라우징 등 응용 프로그램도 포함됩니다. 즉, 사용자의 요청에 따라 데이터를 생성, 조작, 제어하고, 응용 프로그램 간 메시지를 전송하는 역할을 합니다.
대부분의 기존 환경에서는 데이터를 테이프에 백업하여 정기적으로 오프사이트로 전송합니다. 이 방법을 사용할 경우, 가동 중단 발생 시 시스템을 복원하는 데 많은 시간이 걸릴 수 있습니다.
S3는 백업에 빠르게 액세스할 수 있는 이상적인 대상 위치입니다. S3와 데이터를 주고받는 과정은 주로 네트워크를 통해 이뤄지므로 어떤 위치에서든 액세스가 가능합니다. 또한 수명 주기 정책을 사용하여 오래된 백업을 더 비용 효율적인 스토리지 클래스로 순차 이동할 수 있습니다.
기본적인 작동 방식은 다음과 같습니다.
원격 서버 데이터가 S3의 한 공간(Ex_ /mybucket)에 백업됩니다.
수명 정책에 따라 일정시간 S3에 보관됐다 이동합니다. [ S3 > S3 Standard-IA > S3 Glacier ]
원격 서버에 장애가 발생하면 재해 복구 VPC를 배포해 서비스를 복원합니다.
CloudFormation을 사용해 주요 네트워킹 배포 자동화
원격 서버와 일치하는 AMI를 사용해 EC2 인스턴스 생성
S3에서 백업을 검색해 시스템 복원
DNS 레코드를 AWS 가리키도록 조정
2. 파일럿 라이트
파일럿 라이트 접근 방식에서는 환경 간에 데이터를 복제하고 핵심 워크로드 인프라의 복사본을 프로비저닝합니다. 이 예에서는 프로덕션 웹 서버, 앱 서버 및 데이터베이스를 복구 환경에 복제합니다. Route 53은 모든 트래픽을 프로덕션 환경으로 라우팅합니다.
데이터 복제 및 백업을 지원하는 데 필요한 리소스(Ex_ DB, 객체 스토리지)는 상시 작동하고 있습니다. 애플리케이션 서버 등의 기타 요소는 애플리케이션 코드와 구성을 통해 로드되지만 꺼져 있으며 재해 복구 장애 조치 호출 시나 테스트 중에만 사용됩니다. 백업 및 복원 방식과는 달리 핵심 인프라는 항상 사용 가능합니다. 애플리케이션 서버를 가동하고 스케일 아웃하여 전체 규모 프로덕션 환경을 빠르게 프로비저닝할 수 있는 옵션이 항상 있습니다.
파일럿 라이트 아키텍처는 비교적 저렴하게 구현할 수 있습니다. 재해 복구의 준비 단계에서 데이터 마이그레이션과 영구 스토리지를 지원하는 서비스 및 기능의 사용을 고려한느 것이 중요합니다.
재해가 발생하면 복구 환경의 서버가 시작됩니다. 그러면 Route 53이 프로덕션 트래픽을 복구 환경으로 전송하기 시작합니다. 필수적인 인프라에는 DNS, 네트워킹 기능 및 다양한 EC2 기능이 포함됩니다.
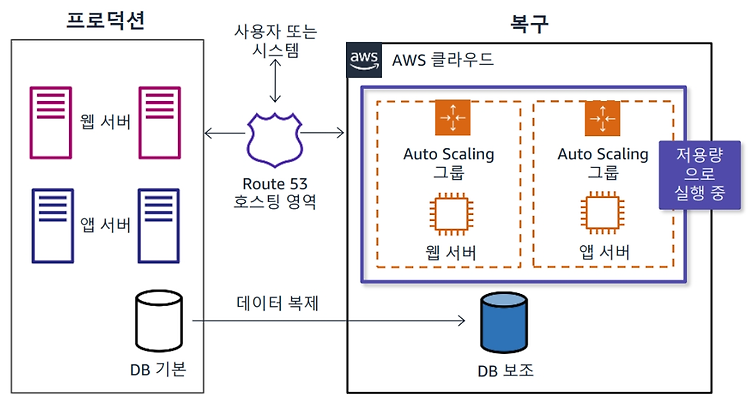
3. 웜 스탠바이
웜 스탠바이 방식에서는 정상 작동하는 축소된 프로덕션 환경 사본을 복구 환경에 생성합니다. 비즈니스 크리티컬한 시스템을 확인한 후 AWS 상에 이러한 시스템을 모두 복제하고 상시 접속되도록 합니다. 따라서 복구 환경의 리소스가 시작될 때까지 기다리지 않아도 되므로 복구 시간이 단축됩니다.
이 예시에서는 웹 서버와 앱 서버를 Auto Scaling 그룹으로 복구 환경에 복제합니다. Auto Scaling 그룹은 실행 가능한 최소 수의 인스턴스와 가장 작은 EC2 인스턴스 크기를 실행할 수 있습니다. 이 솔루션은 최대 프로덕션 로드를 처리할 정도로 크기가 조정되지 않지만 기능은 온전하게 작동합니다. 이 솔루션은 최대 프로덕션 로드를 처리할 정도로 크기가 조정되진 않지만 기능은 온전하게 작동합니다. 이 솔루션은 테스트, 품질 보장 및 내부 사용 등 프로덕션 이외의 작업에 사용할 수 있습니다. Route 53을 사용해 프로덕션 환경과 복구 환경 간에 요청을 분산합니다. 그런 다음 복구 환경에 데이터베이슬르 복사하고 데이터 복제를 사용하여 해당 데이터 베이스를 최신 상태로 유지합니다.
위 다이어그램에서 프로덕션 환경과 복구 환경에서 실행중인 저용량 시스템이 있습니다. 복구 환경을 웜 스탠바이 상태로 유지하려면 모든 필수 구성 요소가 프로덕션 트래픽에 맞게 크기가 조정되지 않은 상태로 계속 실행돼야 합니다. 따라서 모범 사례에 따라 DR 사이트로 전송되는 프로덕션 트래픽의 하위 세트를 사용하여 지속적으로 테스트를 진행해야 합니다.
프로덕션 환경을 사용할 수 없으면 Route 53은 복구 환경으로 전환합니다. 프라이머리 시스템에서 장애가 발생하면 복구 환경은 자동으로 용량을 확장합니다.
중요한 로드의 경우, 장애 발생 시 대기 영역의 워크로드를 중지하고, 주요 영역의 워크로드를 대기 영역으로 복제한 후 다시 시작합니다. 따라서 RTO는 장애 조치 소요 시간만큼만 소요됩니다.
나머지 로드의 경우, 장애 발생 시 대기 영역의 워크로드를 운영 수준으로 스케일 업합니다. 따라서 RTO는 스케일 업하는 데 걸리는 시간만큼 소요됩니다.
복제 유형은 데이터를 대기 영역으로 복제하는 방법을 의미합니다. 즉시 복제, 주기적 복제, 변경 사항만 복제 등의 방법이 있습니다. RPO는 복제 유형에 따라 달라지므로, 중요한 로드의 경우 즉시 복제, 나머지 로드의 경우 주기적 복제 또는 변경 사항만 복제하는 방법을 사용하는 것이 일반적입니다.
다중 사이트 액티브-액티브
액티브-액티브 구성에서는 다중 사이트 솔루션이 2개 환경에서 실행됩니다.
위 예에서는 프로덕션 A 및 프로덕션 B 환경에서 웹 서버, 앱 서버, DB를 실행하여 프로덕션 트래픽을 처리합니다. Route 53은 두 환경 간에 트래픽을 라우팅합니다.
이 아키텍처는 잠재적으로 가동 중단 시간이 가장 짧습니다. 하지만 더 많은 환경이 실행되므로 비용도 더 많이 듭니다. Route 53과 같은 가중치 기반 라우팅을 지원하는 DNS 서비스를 사용하면 프로덕션 트래픽을 동일한 애플리케이션이나 서비스를 제공하는 다른 사이트로 라우팅할 수 있습니다.
A 환경에서 재해가 발생할 경우 DNS 가중치를 조정하여 B 환경으로 모든 트래픽을 전송할 수 있습니다. 또한, 최대 프로덕션 로드를 처리할 수 있도록 AWS 서비스 용량을 신속하게 증가시킬 수 있습니다. EC2 Auto Scaling을 사용하면 이 프로세스를 자동으로 실행할 수 있습니다. 프라이머리 DB 서비스의 장애를 감지하고 AWS에서 실행되는 병렬 DB 서비스로 이관되기 위해 몇 가지 애플리케이션 로직이 필요할 수 있습니다.
이 패턴은 잠재적으로 가동 중단 시간이 가장 짧습니다. 하지만 더 많은 시스템이 실행되므로 비용도 더 많이 듭니다. 이 시나리오의 비용은 정상 운영 중 AWS가 처리하는 프로덕션 트래픽의 양에 따라 결정됩니다. 복구 단계에서는 전체 재해 복구 환경이 필요한 기간 동안 트래픽을 실제로 사용한 만큼만 비용을 지불하면 됩니다. 비용을 더욱 줄이려면 상시 작동해야 하는 AWS 서버에 대해 EC2 예약 인스턴스를 구입하면 됩니다.
AWS에서 흔히 사용되는 DR 사례 비교
심각한 재해가 발생하더라도 비즈니스 연속성을 통해 중요한 비즈니스 기능이 계속 빠르게 작동하거나 복구됩니다. 애플리케이션은 복잡성의 스펙트럼에 배치할 수 있습니다.
위 그림은 재해 복구 이벤트가 발생한 후 얼마나 빨리 사용자에게 시스템을 사용 가능한 상태로 다시 제공할 수 있는지에 따라 4가지 시나리오로 분류한 스펙트럼입니다. 이 예시는 접근 방식 중 하나일 뿐으로 여러 다른 변형 및 조합도 가능합니다.
재해의 경우 파일럿 라이트와 웜 스탠바이 모두 데이터 손실을 제한하는 기능(RPO)을 제공합니다. 둘 다 가동 중단 시간을 제한할 수 있는 충분한 RTO 성능을 제공합니다. 두 전략 중에서 RTO 또는 비용 측면에서 최적화하는 선택을 하면 됩니다.
AWS Backup은 완전관리형 백업 서비스로, AWS 서비스 전체에 걸쳐 데이터 백업을 중앙 집중화하고 자동화할 수 있습니다. AWS Backup은 또한 고객이 규제 규정 준수 의무를 지원하고 비즈니스 연속성 목표를 충족하는 데 도움이 됩니다.
AWS Backup은 AWS Organizations와 연동합니다. 중앙에서 데이터 보호 정책을 배포하여 백업 활동을 구성, 관리 및 제어할 수 있습니다. AWS Backup은 Amazon EC2 인스턴스와 Amazon EBS 볼륨을 비롯한 여러 AWS 계정과 리소스에서 작동합니다. DynamoDB 테이블, Amazon DocumentDB 및 Amazon Neptune 그래프 데이터베이스, Amazon RDS 데이터 베이스(Aurora DB 클러스터 포함) 등 데이터베이스를 백업할 수 있습니다. 그리고 EFS, S3 Storage Gateway 볼륨 및 모든 FSx 버전(FSx for Lustre 및 FSx windows File Servcer 포함)도 백업 가능합니다.
AWS Backup 이점
간편성 AWS에서는 백업 계획을 간편하게 작성할 수 있습니다. AWS Backup 사용 시에는 다른 도구와 달리 사용자 지정 백업 스크립트가 필요하지 않습니다. 그리고 백업을 관리 및 모니터링할 수 있는 중앙 위치가 제공됩니다. AWS Backup 계획은 백업을 정의하는 규칙의 집합입니다. 규칙에는 백업 시작 시점, 백업 기간, 보존 기간이 포함됩니다. AWS Backup의 핵심 기능 중 하나는 태그를 사용해 보호하려는 리소스의 백업을 조정하는 기능입니다.
규정 준수 백업 정책을 적용하고 백업을 암호화할 수 있으며, 수동으로 삭제할 수 없도록 백업을 보호할 수 있습니다. 또한 백업 수명 주기 설정도 방지할 수 있습니다. 여러 AWS 서비스의 통합 백업 활동 로그를 사용해 규정 준수 감사를 수행할 수 있습니다. AWS Backup은 PCI(Payment Cardr Industry) 및 ISO(International Organization for Standardization) 표준을 준수하며, HIPAA(Health Insurance Portability and Accpuntability Act)에 따르는 솔루션입니다.
비용 제어 AWS Backup을 사용해 기업에 피해를 줄 수 있는 가동 중지 발생 위험을 줄일 수 있습니다. 또한 수동 구성에 소요되는 시간을 단축하고 백업을 자동화하여 운영 비용도 줄일 수 있습니다.
AWS Backup 작동 방식
백업 계획을 생성할 때는 다음 사항을 지정합니다.
일정 - 백업 빈도와 백업을 수행할 기간을 설정합니다.
수명 주기 - 백업을 콜드 스토리지로 이동할 시기와 백업 만료 시기를 결정합니다.
저장소 AWS Backup에서는 백업이 AWS Backup 저장소에 보관됩니다. 백업 계획에서 사용할 백업 저장소를 지정해야 합니다. 백업 저장소를 생성할 때는 자체 암호화 방법이 없는 백업에 암호화를 추가하기 위해 AWS KMS(Key Management Service) 암호화 키를 배정합니다.
백업용 태크 - 이 계획을 통해 생성되는 백업에 배정할 태그를 지정합니다.
백업 계획을 사용하여 백업할 리소스를 배정합니다. 또한 AWS Backup에서 이러한 리소스에 대해 필요한 액세스 권한을 얻기 위해 사용할 IAM 역할도 정의해야 합니다. 다음 방법을 사용해 리소스를 배정할 수 있습니다.
태그 - 태그 값을 제공할 수 있습니다. 그러면 해당 태그가 지정된 모든 AWS 리소스는 이 계획을 통해 백업됩니다.
리소스 ID - 특정 DynamoDB 테이블이나 EBS 볼륨 등의 특정 리소스에는 리소스 ID를 사용할 수 있습니다.
AWS Backup은 CloudWatch, EventBridge, CloudTrail, SNS(Simple Notification Service) 등의 다른 AWS 서비스를 사용하여 워크로드를 모니터링합니다.
재해 복구에 대한 방법론적인 접근을 하기 전에, 이와 관련돼있는 AWS 서비스 및 기능을 정리하겠습니다.
DR을 계획할 때는 데이터 마이그레이션과 영구 스토리지를 지원하는 서비스 및 기능의 사용을 고려합니다. AWS에서 시스템의 스케일다운 또는 최대 스케일링 배포가 수반되는 일부 시나리오의 경우, 컴퓨팅 리소스가 필요할 수도 있습니다.
재해 발생 중에는 새로운 리소스를 프로비저닝하거나 사전 구성된 기존 리소스에 대해 장애 조치를 진행할 필요가 있습니다. 이러한 리소스에는 코드와 콘텐츠가 포함됩니다. 하지만 이러한 리소스는 DNS 항목, 네트워크 방화벽 규칙 및 가상 머신 또는 인스턴스와 같은 다른 구성 요소도 포함합니다.
스토리지 복제
백업 전략을 구축할 떄는 복구 요구 사항을 충족하는 솔루션을 사용하여 스토리지를 복제할 계획을 수립해야 합니다. AWS에서는 다음과 같은 스토리지 내 데이터 복제 옵션을 제공합니다.
S3(Simple Storage Service) 미션 크리티컬 및 기본 데이터 슽노리지에 적합하게 설계되고 내구성이 우수한 스토리지를 제공합니다. S3 교차 리전 복제는 버킷 수준의 구성에 속하며, 이러한 구성을 통해 서로 다른 AWS 리전에 있는 여러 버킷에서 객체를 복사할 수 있습니다.
S3 Glacier 데이터 아카이빙 및 백업용 저가형 스토리지를 제공합니다. 몇 시간의 검색 시간이 적합한 경우 아카이브는 자주 액세스하지 않는 데이터에 최적화돼 있습니다.
EBS(Elastic Block Store) 데이터 볼륨의 특정 시점 스냅샷을 생성하는 기능을 제공합니다. 스냅샷 상태가 Completed인 경우 한 AWS 리전에서 다른 리전으로 또는 동일한 리전 내에서 스냅샷을 복사할 수 있습니다.
Snow 패밀리 스토리지 디바이스를 사용하여 고객과 AWS 간에 TB에서 PB 규모의 데이터를 이동할 수 있는 데이터 전송 솔루션 패밀리입니다. Snow 패밀리 디바이스는 고속 인터넷 사용 시보다 훨씬 더 빠르게 S3에 저장된 데이터를 복원하는 데 도움이 됩니다.
DataSync 온프레미스 또는 클라우드 내 파일 시스템의 파일을 EFS(Elastic File System)과 동기화합니다. DataSync는 인터넷 또는 Direct Connect 연결을 통해 데이터를 복사합니다.
복구용 AMI 구성
사용자가 제어하는 가상 머신을 신속하게 생성할 수 있는 기능은 재해 복구 관점에서 매우 중요합니다. 별도의 가용 영역에서 인스턴스를 시작함으로써 단일 위치에서 장애가 발생할 경우 애플리케이션을 보호할 수 있습니다.
기본 하드웨어의 시스템 상태 확인이 실패할 경우, EC2 인스턴스의 자동 복구를 준비할 수 있습니다. 인스턴스는 재부팅되며 필요한 경우 새 하드웨어에서도 가능합니다. 그러나 해당 인스턴스 ID, IP 주소, 탄력적 IP 주소, EBS 볼륨 연결 및 그 밖의 구성 세부 정보는 그대로 유지됩니다. 복구가 완료되려면 초기화 프로세스의 일환에서 인스턴스가 어떤 서비스 또는 애플리케이션을 자동으로 시작하는지 여부를 점검해야 할 것입니다.
AMI(Amazon Machine Image)에는 운영 체제가 사전 구성돼 있고 일부 사전 구성된 AMI에는 애플리케이션 스택도 들어있습니다. 또한 나만의 AMI를 구성할 수도 있습니다. 재해 복구의 측면에서 AWS는 사용자가 나만의 AMI를 구성하고 식별한 후 복구 절차의 일환으로 이러한 AMI를 실행할 것을 적극 권장하고 있습니다. AMI는 사용자가 선택한 운영 체제 및 적절한 애플리케이션 스택으로 사전 구성해야 합니다.
장애 조치 네트워크 설계
재해 대응 시에는 다른 사이트로의 장애 조치를 진행해야 할 수 있습니다. 이렇게 하려면 장애 조치를 시작하도록 네트워크 설정을 수정해야 합니다. 그리고 장애 조치 사이트 내의 네트워크 설정도 조정해야 할 수 있습니다. AWS는 네트워크 설정을 관리하고 수정하는 데 사용할 수 있는 다양한 서비스와 기능을 제공합니다.
Route 53 다수의 글로벌 로드 밸런싱 기능이 포함돼 있습니다. 이는 다수의 엔드포인트와 S3에서 호스트되는 정적 웹 사이트 간에 장애 조치를 싱행하는 기능인 DNS 엔드포인트 상태 확인을 다룰 때 효과적일 수 있습니다.
ELB(Elastic Load Balancing) 수신되는 애플리케이션 트래픽을 여러 EC2 인스턴스에 자동으로 분산합니다. 즉, 수신되는 애플리케이션 트래픽에 응답하는 데 필요한 로드 밸런싱 용량을 ELB가 제공하므로 애플리케이션 내결함성을 높일 수 있습니다. 로드 밸런서를 사전 구성하여 해당 DNS 이름을 식별하고 재해 복구 계획을 실행할 수 있습니다. Rote 53 및 ELB는 기본적으로 고가용성 리소스입니다.
VPC(Virtual Private Cloud) 재해 복구 맥락에서 VPC를 사용하면 기존 네트워크 토플로지를 클라우드로 확장할 수 있습니다. 이는 대체로 내부 네트워크에 위치한 엔터프라이즈 애플리케이션을 복구할 때 매우 적합할 수 있습니다.
Direct Connect 고객 온프레미스 환경에서 AWS로 전용 네트워크 연결을 설정합니다. 이 서비스는 네트워크 비용을 줄이고 대역폭 처리량을 높이며 인터넷 기반 연결보다 더 일관된 네트워크 환경을 제공할 수 있습니다.
데이터베이스 백업 및 복제본
RDS에서는 다음 방법을 사용해 고가용성을 계획할 수 있습니다.
Multi-AZ DB 인스턴스 배포를 생성합니다. 이 배포에서는 장애 조치를 지원하기 위해 프라이머리 인스턴스와 대기 인스턴스가 생성됩니다. 그러나 대기 인스턴스는 트래픽을 처리하지 않습니다.
Multi-AZ DB 클러스터 배포를 생성합니다. 이 배포에서는 읽기 트래픽도 처리 가능한 대기 인스턴스 2개가 생성됩니다.
스냅샷을 사용하여 다른 리전에 읽기 전용 복제본을 생성합니다. 재해 발생 시 이 복제본을 프라이머리로 승격할 수 있습니다. 단, 읽기 전용 복제본을 승격시키려면 시스템을 재부팅해야 합니다. 이 방식의 RTO는 대기 인스턴스로 장애 조치하는 방식보다 더 높습니다.
별도의 리전에 수동 DB 스냅샷 또는 DB 클러스터 스냅샷을 저장합니다.
최대 20개의 AWS 계정과 수동 스냅샷을 공유합니다.
MySQL 및 MariaDB용 Amazon RDS 읽기 전용 복제본은 Multi-AZ 배포를 지원합니다. 데이터베이스의 세컨더리 복사본을 실행하면 복원력 있는 재해 복구 전략을 수립하고 DB 엔진 업그레이드 프로세스를 간소화할 수 있습니다.
DynamoDB 글로벌 풋프린트를 기반으로 굴축된 글로벌 테이블은 다음과 같은 기능을 제공합니다.
DynamoDB 테이블을 복제하는 완전관리형 다중 리전, 다중 활성 DB입니다.
선택한 AWS 리전에서 DynamoDB 테이블의 복제본 읽기 전용 복제본 및 세컨더리 인스턴스와 달리 DynamoDB는 글로벌 테이블의 모든 복제본을 단일 단위로 처리하며, 각 테이블에는 같은 테이블 이름과 프라이머리 키가 사용됩니다. 복제본 하나에서 장애가 ㅂ라생하면 다른 리전의 복제본을 사용하여 데이터에 액세스할 수 있습니다.
템플릿 및 스크립트
재해 복구에서는 시간이 매우 중요합니다. CloudFormation 템플릿 및 스크립팅을 사용하여 리소스를 효율적으로 배포합니다. CloudFormation을 사용해 인프라를 정의하고 여러 AWs 계정 및 리전에 일관되게 배포합니다. CloudFormation은 사전 정의된 의사 파라미터를 사용하여 CloudFormation이 배포된 AWS 계정 및 AWS 리전을 식별합니다. CLoudFormation 템플릿에 조건 논리를 구현하여 재해 복구 리전에 스케일 다운된 버전의 인프라를 배포할 수 있습니다.
EC2 인스턴스 배포의 경우 AMI가 하드웨어 구성 및 설치된 하드웨어에 대한 정보를 제공합니다. 필요한 AMI를 생성하는 EC2 Image Builder 파이프라인을 구현할 수 있습니다. 이들을 프라이머리 및 백업 리전 모두에 복사하면 새 리전에서 워크로드를 재배포 또는 확장하는 데 필요한 모든 항목이 제공됩니다.
EC2 인스턴스를 시작하거나 다른 AWS 리소스를 프로비저닝하려면 AWS CLI(Command Line Interface) 또는 AWS SDK를 사용하여 스크립트를 생성할 수 있습니다.
모든 재해 복구(DR) 계획이 동일하게 생성하는 것은 아니며 많은 계획이 실패합니다. 보다 나은 재해 복구를 위해 테스트, 리소스 및 절차를 고려해 계획을 마련해야 합니다.
테스트 DR 계획을 테스트하여 구현을 검증해야 합니다. 정기적으로 워크로드의 DR 리전으로 장애 조치를 테스트하여 복구 목표가 충족되는지 확인합니다. 드믈게 실행되는 복구 경로는 개발하지 않는 것이 좋습니다. 예를 들어 읽기 전용 쿼리에만 사용되는 세컨더리 데이터 스토어가 있을 수 있습니다. 기본 데이터 스토어에 장애가 발생했을 때 세컨더리 데이터 스토어로 장애 조치되도록 계획합니다.
리소스 정기적으로 복구 경로를 프로덕션 환경에서 실행해야 합니다. 이를 통해 복구 경로의 유효성이 검사되고 이벤트 동안 리소스가 운영에 충분한지 확인하는 데 도움이 됩니다. 프로덕션 호나경에서의 구성 변경을 DR 네트워크에도 동기화해야 합니다.
계획 복구 계획은 주기적으로 테스트를 해야만 제대로 작동합니다. 보조 리소스의 용량은 마지막으로 테스트 했을 때는 충분했더라도 운영 횐경 변화에 의해 더 이상 로드를 감당하지 못할 수 있습니다. 따라서 정기적인 테스트를 통해 보조 리소스의 용량이 실제 운영 환경에서 충분한지 확인해야 합니다.
가용성 개념
프로덕션 시스템은 대체로 가동 시간 측면에서 정의됐거나 암묵적인 목표를 갖고 있습니다. 장애 발생 시 가동 중단 시간이 최소화되면 "시스템은 고가용성이다"라고 합니다. 가동 중단 시간은 없앨 수 없지만 몇 초 또는 몇 분으로 단축해야 합니다.
고가용성은 가동 중단 시간 및 비용을 최소화하고 장애로부터 보호합니다. 매우 짧은 가동 중단, 신속한 복구, 낮은 비용으로 비즈니스를 계속 운영할 수 있게 합니다.
내결함성은 고가용성과 자주 혼동하지만 서비스 중단이 발생하지 않도록 애플리케이션 구성 요소에 내장된 중복성을 말합니다. 하지만 비용은 더 많이 듭니다.
백업은 데이터를 보호하고 비즈니스 연속성을 보장하는 데 있어 중요합니다. 그와 동시에, 백업을 제대로 구현하는 것은 까다로운 문제가 될 수 있습니다. 데이터가 생성되는 속도는 기하급수적으로 증가하고 있기 때문입니다. 그러나 로컬 디스크의 밀도 및 내구성은 데이터만큼 빠른 속도로 증가하고 있지는 않습니다. 엔터프라이즈 백업은 그 자체가 하나의 산업이 됐습니다.
재해 복구는 가용성 구성 요소 중 하나로서 간과할 때가 많습니다. 자연재해로 하나 이상의 구성 요소에 장애가 발생하거나 기본 데이터 원본이 손상됐을 때, 데이터 손실 없이 신속하게 서비스를 복구할 수단이 있어야 합니다.
장애 조치와 리전
AWS는 전 세계적으로 여러 리전에서 사용할 수 있습니다. 시스템을 완전하게 배포할 사이트 외에 재해 복구 사이트로 가장 적합한 로케이션을 선택할 수 있습니다. 리전을 이용할 수 없는 경우는 매우 희박합니다. 그러나 매우 큰 규모의 이벤트(자연 재해 등)가 어떤 리전에 영향을 미칠 경우, 그럴 가능성도 있습니다.
AWS는 리전별로 제공하는 현재 제품 및 서비스의 자세한 사이트 페이지를 유지하고 관리합니다. AWS는 한 리전의 어떤 대규모 이벤트가 다른 리전에 영향을 미치지 안도록 엄격한 리전 격리 정책을 유지합니다. 당사는 고객들이 자사의 전략에도 이와 유사한 다중 리전 접근 방식을 취할 것을 권장합니다. 각 리전은 다른 리전에 영향을 미치지 않고 오프라인으로 전환할 수 있어야 합니다.
미국(US) 내 AWS 리전과 연결되는 AWS Direct Connect 회선을 보유하고 있는 경우, 퍼블릭 인터넷을 통한 트래픽 이동 없이 AWS GovCloud(US)를 퐇마한 미국 내 모든 리전에 액세스할 수 있습니다. 또한 애플리케이션 배포 방식도 고려해야 합니다. 각 리전에 개별적으로 애플리케이션을 배포할 경우, 재해 발생 시 해당 리전을 격리하고 모든 트래픽을 다른 리전으로 이전할 수 있습니다.
새로운 애플리케이션과 인프라를 신속하게 배포하는 경우, 액티브-액티브 리전이 필요할 수 있습니다. 어떤 리전의 애플리케이션이 오작동하거나 사용 불가능 상태가 되는 문제를 일으킨 무언가를 배포한다고 가정해 보겠습니다. Route 53의 활성 레코드 세트에서 해당 리전을 제거하고 근본 원인을 확인한 다음, 변경 사항을 롤백한 후에 해당 리전을 다시 활성화할 수 있습니다.
RPO(복구 시점 목표) 및 RTO(복구 시간 목표)
복구 시점 목표(RPO)는 시간 단위로 측정한 허용 가능한 데이터 손실량을 나타냅니다. 예를 들어 어떤 재해가 오후 1:00에 발생하고 RPO가 12시간인 경우 시스템은 당일 오전 1:00에 존재하던 모든 데이터를 복구해야 합니다. 데이터 손식은 최대 12시간(오전 1:00와 오후 1:00 사이)입니다.
복구 시간 목표(RTO)란 운영 수준 계약(OLA)에서 정의한 바와 같이 중단 후 비즈니스 프로세스를 서비스 수준으로 복원하기까지 걸리는 시간을 의미합니다. 예를 들어 어떤 재하가 오후 1:00에 발생하고 RTO가 1시간인 경우 재해 복구 프로세스는 비즈니스 프로세스를 오후 2:00까지 허용 가능한 수준으로 복원해야 합니다.
일반적으로 회사는 시스템을 가동할 수 없을 때 기업에 미칠 재정적 영향에 근거하여 허용 가능한 RPO 및 RTO를 결정합니다. 회사는 가동 중단 시간 및 시스템 가용성 부족으로 인한 사업 손실 및 회사 평판 손상 등 여러 가지 요인들을 고려해 재정적 영향을 평가합니다. IT 조직은 RTO에 따라 수립된 일정 및 서비스 수준 범위 내에서 RPO에 근거해 비용 효율적인 시스템 복구를 제공할 수 있는 솔루션을 계획합니다.
AWS Outposts를 잘 이해하기 위해서는 애플리케이션을 AWS로 마이그레이션할 때 온프레미스로 유지해야하는 애플리케이션이 있는지 생각해보는 것이 좋습니다.
이러한 애플리케이션은 최종 사용자 애플리케이션에 준실시간 응답을 보장해야 할 수 있습니다. 또는 다른 온프레미스 시스템과 통신하거나 현장 장비를 제어해야 할 수 있습니다. 예를 들어 제조 분야에서 자동화된 운영을 위해 공장의 현장에서 실행되는 워크로드, 실시간 환자 진단이나 의료 영상, 콘텐츠 및 미디어 스트리밍이 여기에 포함될 수 있습니다.
온프레미스에서 또는 AWS 리전 외부의 국가에서 유지해야 하는 고객 데이터를 안전하게 저장하고 처리하는 솔루션이 필요합니다. 데이터 분석, 백업 및 복원을 보다 밀접하게 제어하려는 경우 로컬에서 데이터 집약적 워크로드를 실행하고 데이터를 처리해야 합니다.
Outposts 랙 및 Outposts 서버
Outposts를 사용하면 AWS 클라우드를 온프레미스 데이터 센터로 확장할 수 있습니다. Outposts는 다양한 폼 팩터로 제공되며 각각 별도의 요구 사항이 있습니다. 사이트가 주문하려는 폼 팩터의 요구 사항을 충족하는지 확인해야 합니다.
폼 팩터는 제품의 물리적인 외형을 뜻합니다.
Outposts 랙을 주문할 때 다양한 Outposts 구성 중에서 선택할 수 있습니다. 각 구성에서는 EC2 인스턴스 유형과 EBS 볼륨이 함께 제공됩니다.
Outposts 랙 주문을 처리하기 위해 AWS는 고객에게 날짜 및 시간을 예약합니다. 설치 전에 확인 또는 제공할 항목의 체크리스트도 제공됩니다. 팀이 랙을 지정된 위치로 이동하면 전기 기술자가 랙에 전력을 공급할 수 있습니다. 팀은 고객이 제공하는 업링크를 통해 랙에 대한 네트워크 연결을 설정하고 랙의 용량을 구성합니다.
Outposts 서버 사용 시에는 랙보다 소규모로 하드웨어를 주문할 수 있습니다. 이 경우에도 온프레미스에서 AWS 서비스는 계속 제공됩니다. ARM 또는 Intel 기반 옵션 중에서 선택할 수 있습니다. Outposts 랙에서 사용 가능한 모든 서비슥 ㅏOutposts 서버에서 지원되는 것은 아닙니다.
고객에게 직접 배달되는 Outposts 서버는 고객의 온사이트 담장자나 서드 파티 공급 업체가 설치합니다. Outposts 서버가 고객의 네트워크에 연결되면 AWS가 컴퓨팅 및 스토리지 리소스를 원격으로 프로비저닝합니다.
VPC에는 해당 AWS 리전의 모든 가용 영역이 포함됩니다. Outpost 서브넷을 추가하면 리전의 모든 VPC가 Outpost에 포함되도록 확장할 수 있습니다.
Outposts는 여러 서브넷을 지원합니다. Outpost에서 EC2 인스턴스를 시작할 때 EC2 인스턴스 서브넷을 선택합니다. 인스턴스가 배포되어 있는 기본 하드웨어를 선택할 수는 없습니다. Outpost는 AWS 컴퓨팅 및 스토리지 용량이 온프레미스 환경으로 제공되기 때문입니다.
각 Outpost는 여러 VPC를 지원할 수 있으며, 각 VPC는 Outpost 서브넷을 하나 이상 포함할 수 있습니다. Outpost를 생성한 VPC CIDR 범위에서 Outpost 서브넷을 생성합니다. Outpost 서브넷에 있는 EC2 인스턴스와 같은 리소스용 Outpost 주소 범위를 사용할 수 있습니다. AWS는 VPC CIDR 또는 Outpost 서브넷 범위를 온프레미스 로케이션에 직접 알리지 않습니다.
Outpost에서 리소스를 생성하면 온프레미스 데이터 및 애플리케이션과 근접해 실행해야 하는 지연 시간이 짧은 워크로드를 생성할 수 있습니다.