목차
| 1 . CONCAT | 11. RTRIM | 21. REGEXP_REPLACE |
| 2. SUBSTRING | 12. LEFT | 22. NULL 값을 처리하기 위한 함수 |
| 3. LENGTH | 13. RIGHT | 22-1. ISNULL |
| 4. TRIM | 14. REVERSE | 22-2. COALESCE |
| 5. UPPER | 15. ASCII | |
| 6. LOWER | 16. CHAR | |
| 7. REPLACE | 17. STRCMP | |
| 8. POSITION | 18. CONCAT_WS | |
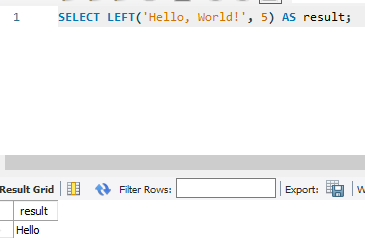
| 9. CHAR_LENGTH | 19. SUBSTR_COUNT | |
| 10. LTRIM | 20. INSTR |
문자열 함수
SQL의 문자열 함수는 문자 데이터를 조작하고 처리하는 데 사용됩니다. 연결, 자르기, 대소문자 변환, 하위 문자열 추출 등을 수행할 수 있습니다. 특정 구문은 DBMS(데이터베이스 관리 시스템)마다 약간씩 다를 수 있지만 대부분의 기본 문자열 함수는 대부분의 DBMS에서 공통적입니다. 다음은 일반적으로 사용되는 SQL 문자열 함수입니다.
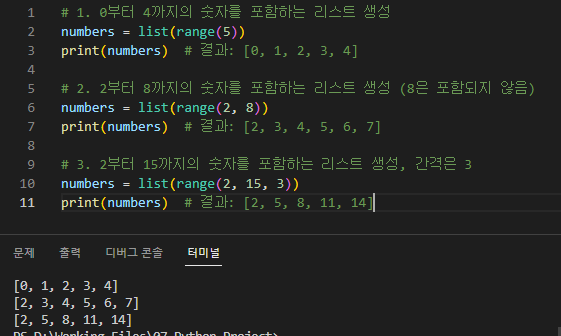
1 . CONCAT(str1, str2, ...): 두 개 이상의 문자열을 연결합니다.
SELECT CONCAT('Hello', ' ', 'World!') AS result;
2. SUBSTRING(str, start, length): 지정된 위치에서 시작하여 지정된 길이로 문자열에서 하위 문자열을 추출합니다.
SELECT SUBSTRING('Hello, World!', 1, 5) AS result;

3. LENGTH(str): 문자열의 길이를 반환합니다.
SELECT LENGTH('Hello, World!') AS result;

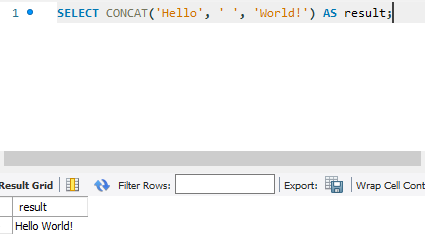
4. TRIM([LEADING | TRAILING | BOTH] [chars] FROM str): 문자열의 처음, 끝 또는 양쪽에서 지정된 문자(또는 기본적으로 공백)를 제거합니다.
SELECT TRIM(' Hello, World! ') AS result;
5. UPPER(str): 문자열을 대문자로 변환합니다.
SELECT UPPER('Hello, World!') AS result;

6. LOWER(str): 문자열을 소문자로 변환합니다.
SELECT LOWER('Hello, World!') AS result;

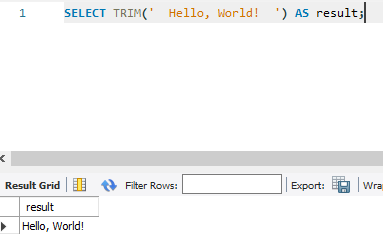
7. REPLACE(str, search_str, replace_str): 검색 문자열의 모든 항목을 입력 문자열의 대체 문자열로 바꿉니다.
SELECT REPLACE('Hello, World!', 'World', 'SQL') AS result;
8. POSITION(substr IN str): 문자열 내에서 하위 문자열이 처음 나타나는 위치를 반환합니다.
SELECT POSITION('World' IN 'Hello, World!') AS result;

9. CHAR_LENGTH(str) 또는 CHARACTER_LENGTH(str): 문자열의 문자 수를 반환합니다. 이 수는 멀티바이트 문자 집합의 바이트 길이와 다를 수 있습니다.
SELECT CHAR_LENGTH('Hello, World!') AS result;
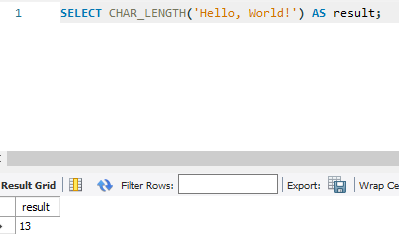
10. LTRIM(str): 문자열에서 선행 공백을 제거합니다.
SELECT LTRIM(' Hello, World!') AS result;
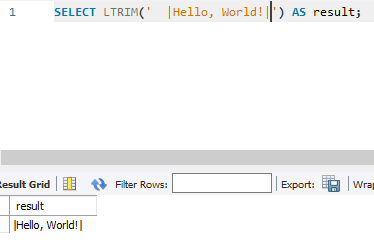
11. RTRIM(str): 문자열에서 후행 공백을 제거합니다.
SELECT RTRIM('Hello, World! ') AS result;
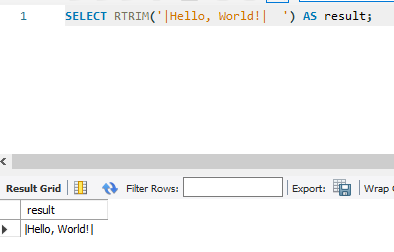
12. LEFT(str, n): 문자열의 왼쪽부터 처음 n자를 반환합니다.
SELECT LEFT('Hello, World!', 5) AS result;
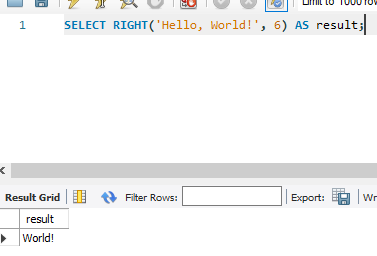
13. RIGHT(str, n): 문자열의 오른쪽부터 처음 n자를 반환합니다.
SELECT RIGHT('Hello, World!', 6) AS result;
14. REVERSE(str): 문자열의 문자를 반대로 바꿉니다.
SELECT REVERSE('Hello, World!') AS result;

15. ASCII(str): 문자열에서 첫 번째 문자의 ASCII 값을 반환합니다.
SELECT ASCII('A') AS result;

16. CHAR(ascii_code): 제공된 ASCII 코드에 해당하는 문자를 반환합니다.
SELECT CHAR(65) AS result;

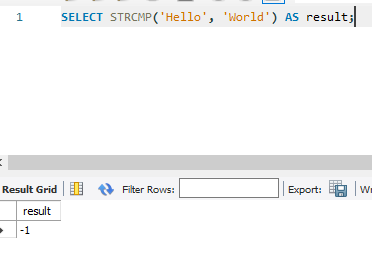
17. STRCMP(str1, str2): 두 문자열을 비교하여 같으면 0, str1이 str2보다 작으면 음수 값, str1이 str2보다 크면 양수 값을 반환합니다.
SELECT STRCMP('Hello', 'World') AS result;
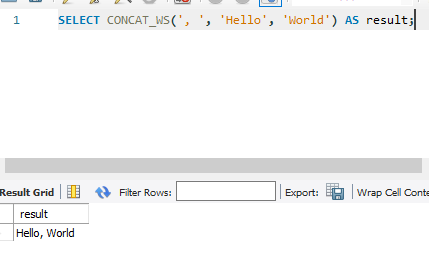
18. CONCAT_WS(separator, str1, str2, ...): 지정된 구분 기호를 사용하여 두 개 이상의 문자열을 연결합니다.
SELECT CONCAT_WS(', ', 'Hello', 'World') AS result;
19. SUBSTR_COUNT(str, substr): 문자열 내 하위 문자열의 발생 횟수를 반환합니다.(SQL에서는 지원하지 않고, Oracle에서 사용됩니다. 대신 3, 7번을 사용하여 비슷한 결과를 얻을 수 있습니다.)
SELECT SUBSTR_COUNT('Hello, World!', 'l') AS result;
20. INSTR(str, substr): 문자열 내에서 하위 문자열이 처음 나타나는 위치를 반환하거나 하위 문자열을 찾을 수 없는 경우 0을 반환합니다.
SELECT INSTR('Hello, World!', 'World') AS result;

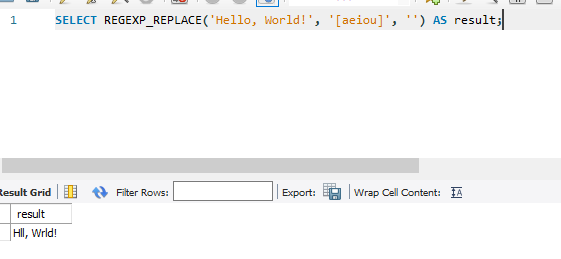
21. REGEXP_REPLACE(str, pattern, replacement): 정규식을 사용하여 문자열 내의 패턴 발생을 지정된 대체 문자열로 바꿉니다.
SELECT REGEXP_REPLACE('Hello, World!', '[aeiou]', '') AS result;
22. SQL은 NULL 값을 처리하기 위한 함수를 제공합니다. 이러한 함수는 기본값을 제공하거나 특정 작업을 수행하여 데이터의 NULL 값을 관리하는 데 도움이 됩니다. 다음은 예제와 함께 각 기능에 대한 설명입니다.
22-1. ISNULL
ISNULL은 SQL Server 및 MySQL 전용 함수입니다. 두 가지 인수가 필요합니다. 첫 번째 인수가 NULL이면 두 번째 인수를 반환합니다. 첫 번째 인수가 NULL이 아니면 첫 번째 인수를 반환합니다. NULL 값을 기본값으로 바꾸는 데 유용합니다.
예시(SQL server 기준)
SELECT ProductID, ProductName, ISNULL(Price, 0) AS Price
FROM Products;
예시(MySQL 기준)
SELECT ProductID, ProductName, IFNULL(Price, 0) AS Price
FROM Products;
두 예에서 ISNULL 함수는 Price 열의 NULL 값을 0으로 바꿉니다.
22-2. COALESCE
COALESCE는 SQL Server, MySQL, PostgreSQL 및 Oracle과 같은 다양한 DBMS에서 작동하는 보다 일반적인 기능입니다. 여러 인수를 사용하고 NULL이 아닌 첫 번째 인수를 반환합니다. 모든 인수가 NULL이면 NULL을 반환합니다.
SELECT ProductID, ProductName, COALESCE(Price, DiscountedPrice, 0) AS Price
FROM Products;
이 예제에서 COALESCE 함수는 각 행에 대해 Price 열과 DiscountedPrice 열을 확인합니다. Price가 NULL이 아니면 Price를 반환합니다. Price가 NULL이면 DiscountedPrice를 확인합니다. DiscountedPrice도 NULL이면 0을 반환합니다. 이러한 방식으로 COALESCE는 NULL 값을 ISNULL 함수보다 유연하게 관리할 수 있도록 도와줍니다.
'SQL' 카테고리의 다른 글
| [SQL] SQL GROUP 함수 (0) | 2023.04.24 |
|---|---|
| [SQL] SQL, SQL server 날짜와 시간 데이터 가져오기 (0) | 2023.04.23 |
| [SQL] MySQL 서브 쿼리(SUBQUERY)란? (0) | 2023.04.23 |
| [SQL] SQL JOIN의 종류와 예시 (0) | 2023.04.23 |
| [MySQL] MySQL 테이블 관련 절과 명령어(GROUP/OTHER BY, HAVING, 테이블 수정/추가/제거) (0) | 2023.04.23 |